
로컬 LLM 서빙 엔진을 고를 때 이제 선택지는 Ollama와 vLLM만이 아닙니다. 괴발자 채널의 영상 「Ollama 보다 빠르다는 vLLM을 뛰어넘었습니다! 로컬 LLM 서빙 엔진 SGLang 소개」는 SGLang이 왜 주목받는지, 그리고 어떤 상황에서 검토할 만한지 쉽게 보입니다.
Read in English: SGLang for Local LLM Serving: Is It the Next Step After Ollama and vLLM?
SGLang 로컬 LLM 서빙 엔진이 주목받는 이유
영상의 출발점은 간단합니다. vLLM이 Ollama보다 빠르다고 알려졌지만, SGLang은 특정 조건에서 vLLM보다 더 높은 처리량과 낮은 지연시간을 목표로 합니다.
단순 실행 도구가 아니라 서비스용 엔진에 가깝다
Ollama는 로컬에서 모델을 빠르게 실행하고 테스트하기에 편합니다. 반면 SGLang과 vLLM은 여러 요청을 동시에 처리하는 서빙 상황을 더 강하게 의식합니다. 그래서 개인 실험보다 기업 내부 챗봇, RAG, AI 에이전트, API 서비스처럼 동시 요청이 생기는 환경에서 차이가 커집니다.
생태계 신호도 무시하기 어렵다
영상은 SGLang이 LMSYS 팀에서 시작했고, Grok, NVIDIA 지원, 글로벌 기업 채택 사례와 연결된다고 설명합니다. 오픈소스 LLM 인프라에서는 성능뿐 아니라 생태계 신뢰가 더 봐야 합니다. 문서, GPU 지원, 운영 사례가 늘어날수록 실무 도입 장벽이 낮아지기 때문입니다.
핵심 원리: RadixAttention은 무엇을 줄이나
SGLang을 이해할 때 가장 중요한 키워드는 RadixAttention입니다. 영상에서는 여러 요청이 완전히 달라 보이더라도 앞부분의 시스템 프롬프트나 공통 지시문은 반복되는 경우가 많다고 설명합니다.
공통 프롬프트를 다시 계산하지 않는다
예를 들어 기업 챗봇은 매 요청마다 “당신은 회사 내부 문서를 바탕으로 답변하는 AI입니다” 같은 시스템 지시문을 붙일 수 있습니다. 사용자의 질문은 달라도 앞부분은 같습니다. RadixAttention은 이런 공통 접두부를 재사용해 불필요한 계산을 줄이는 방식으로 이해하면 쉽습니다.
RAG와 에이전트 서비스에서 의미가 커진다
RAG 서비스나 AI 에이전트는 공통 지시문, 도구 사용 규칙, 출력 형식이 반복되는 경우가 많습니다. 이때 같은 문맥을 계속 계산하면 GPU 시간과 응답 지연이 늘어납니다. SGLang은 이런 반복 구조가 많은 서비스에서 장점을 낼 가능성이 높습니다.
Ollama·vLLM·SGLang 비교 결과를 어떻게 볼까
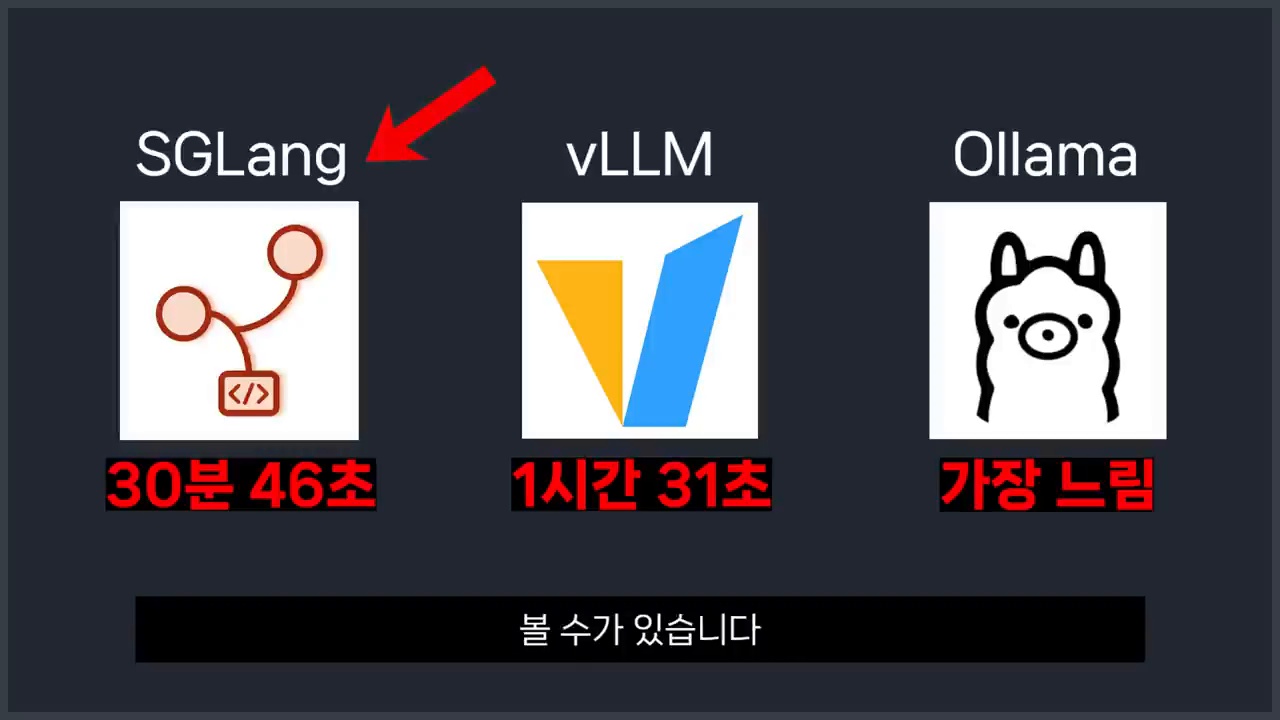
영상에서는 같은 모델을 기준으로 Ollama, vLLM, SGLang을 비교합니다. 결과만 보면 SGLang이 가장 빠르고, vLLM이 그다음이며, Ollama는 상대적으로 느리게 나타납니다.
숫자는 강하지만 조건을 함께 봐야 한다
성능 비교는 항상 환경 의존적입니다. GPU 종류, 모델 크기, 동시 요청 수, 프롬프트 길이, 배치 방식에 따라 결과가 달라질 수 있습니다. 그래서 영상의 결과는 “모든 경우에 SGLang이 정답”이라는 뜻이 아닙니다. 대신 동시 요청과 반복 문맥이 많은 환경에서는 SGLang을 벤치마크 후보에 넣어야 한다는 신호로 보는 편이 안전합니다.
vLLM의 장점도 여전히 크다
vLLM은 이미 널리 쓰이는 고성능 LLM 서빙 엔진입니다. 문서와 사례가 풍부하고, 범용적인 배치 처리 성능도 강합니다. SGLang이 흥미로운 선택지라고 해서 vLLM의 가치가 사라지는 것은 아닙니다. 실무에서는 두 엔진을 같은 요청 패턴으로 테스트해 보는 것이 더 합리적입니다.
상황별 선택 기준: 무엇을 쓰면 좋을까
SGLang을 도입할지 판단하려면 “내가 어떤 문제를 풀고 있는가”를 먼저 봐야 합니다. 개인 실험, 사내 PoC, 실제 서비스는 요구 조건이 다릅니다.
개인 테스트라면 Ollama가 여전히 편하다
로컬에서 모델을 설치하고 간단히 프롬프트를 테스트하는 목적이라면 Ollama의 편의성이 큽니다. 설치와 실행이 단순하고, 개발자가 빠르게 모델을 바꿔볼 수 있습니다. 성능보다 접근성과 반복 실험 속도가 중요할 때 적합합니다.
일반 서비스 서빙은 vLLM부터 검토할 수 있다
이미 vLLM을 쓰고 있거나 범용적인 고성능 API 서버가 필요하다면 vLLM은 여전히 좋은 출발점입니다. 운영 자료와 커뮤니티 경험이 많기 때문에 장애 대응과 튜닝 정보를 찾기 쉽습니다.
반복 문맥이 많은 대량 요청은 SGLang을 검토하자
SGLang은 공통 프롬프트가 반복되는 챗봇, RAG, 에이전트, 다중 사용자 서비스에서 매력적입니다. 요청마다 비슷한 시스템 지시문과 출력 규칙이 들어간다면 RadixAttention의 이점이 커질 수 있습니다.

도입 전 체크리스트
SGLang을 바로 운영 환경에 넣기보다는 작은 PoC로 검증하는 편이 좋습니다.
- 같은 모델과 같은 프롬프트 세트로 vLLM과 SGLang을 비교한다.
- 단일 요청 속도뿐 아니라 동시 요청 처리량을 함께 측정한다.
- 공통 시스템 프롬프트가 많은 실제 요청 로그를 샘플링한다.
- GPU 메모리 사용량과 장애 복구 방식을 확인한다.
- 운영팀이 설치, 배포, 모니터링을 감당할 수 있는지 점검한다.
벤치마크는 평균보다 꼬리 지연시간을 보자
서비스에서는 평균 응답 시간보다 p95, p99 같은 꼬리 지연시간이 중요할 때가 많습니다. 일부 요청이 지나치게 늦어지면 사용자는 전체 서비스가 느리다고 느낍니다. SGLang을 테스트할 때도 처리량, 평균 지연시간, 꼬리 지연시간을 함께 봐야 합니다.
결론: SGLang은 ‘서비스형 로컬 LLM’의 후보군이다
SGLang 로컬 LLM 서빙 엔진은 Ollama의 편의성과 vLLM의 범용 성능 사이에서, 반복 문맥과 대량 요청 처리에 초점을 둔 선택지로 볼 수 있습니다. 모든 팀에 정답은 아니지만, RAG나 AI 에이전트처럼 비슷한 프롬프트 구조가 반복되는 서비스라면 충분히 테스트해 볼 가치가 있습니다.
원본 영상은 괴발자 채널의 「Ollama 보다 빠르다는 vLLM을 뛰어넘었습니다! 로컬 LLM 서빙 엔진 SGLang 소개」입니다. AI 인프라와 로컬 LLM 관련 글은 ThinkNote AI 카테고리에서도 함께 확인할 수 있습니다.
FAQ
SGLang은 Ollama를 대체하나요?
완전한 대체라기보다 목적이 다릅니다. Ollama는 로컬 실행과 실험이 쉽고, SGLang은 여러 요청을 처리하는 서빙 환경에 더 초점을 둡니다.
vLLM을 이미 쓰고 있어도 SGLang을 봐야 하나요?
동시 요청이 많고 공통 프롬프트가 반복된다면 비교 테스트를 해볼 만합니다. 주의할 점은 기존 vLLM 운영이 안정적이라면 실제 요청 로그 기반으로 이득을 확인한 뒤 전환하는 것이 좋습니다.
SGLang은 어떤 서비스에 잘 맞나요?
기업 내부 챗봇, RAG, AI 에이전트, 반복 지시문이 많은 API 서비스에 잘 맞을 수 있습니다. 반대로 단순 개인 실험이라면 Ollama가 더 편할 수 있습니다.
참고자료
- 괴발자 YouTube 영상: Ollama 보다 빠르다는 vLLM을 뛰어넘었습니다! 로컬 LLM 서빙 엔진 SGLang 소개
- SGLang 공식 GitHub
- LMSYS 공식 홈페이지
- PyTorch Blog: SGLang joins PyTorch
- NVIDIA NGC: SGLang container