
로컬 LLM은 이제 “재미로 돌려보는 장난감”을 넘어 실제 업무 도구가 될 수 있을까요. 배움의 달인 영상은 M5 Pro Max 128GB 환경에서 OMLX 서버, Claude Code, Hermes Agent를 연결해 이 질문을 직접 테스트합니다.
먼저 볼 부분은 단순합니다. 로컬 LLM이 모든 클라우드 모델을 대체한다는 이야기가 아닙니다. 반복 작업, 빠른 초안, 일부 코딩 보조, 개인 지식 기반 검색처럼 비용·속도·프라이버시가 중요한 영역부터 로컬로 옮길 수 있는지가 관건입니다.
Read in English: This article is also available in English for global readers.
영상이 던진 핵심 질문: 로컬 LLM은 실무에 쓸 수 있나
이 영상의 검색 의도는 “M5 Pro Max에서 로컬 LLM이 빠른가?”에만 머물지 않습니다. 더 중요한 질문은 세 가지입니다.
- 로컬 모델을 Claude Code 같은 개발 도구와 연결할 수 있는가
- OMLX 같은 서버가 체감 속도를 얼마나 끌어올리는가
- Hermes Agent처럼 도구를 호출하는 에이전트에도 로컬 LLM을 붙일 수 있는가
영상에서는 Qwen 계열 모델, NVIDIA Nemotron Nano 계열 모델, 임베딩 모델 등을 소개하며 로컬 환경을 하나의 작업 시스템처럼 구성합니다. 여기서 로컬 LLM은 단일 챗봇이 아니라 여러 도구와 연결되는 백엔드 모델에 가깝습니다.
Thinknote의 세컨드 브레인과 LLM Wiki 글에서 다룬 것처럼, 앞으로의 AI 활용은 모델 성능만이 아니라 “어떤 맥락을 어떤 도구와 연결하느냐”가 더 더 봐야 합니다.
OMLX가 중요한 이유: 모델보다 서버 체감이 먼저 보인다
영상에서 가장 눈에 띄는 장면은 OMLX 대시보드입니다. 진행자는 OMLX를 통해 초당 117토큰 수준의 생성 속도를 확인했다고 설명합니다. 수치 자체보다 먼저 볼 부분은 로컬 LLM의 병목이 모델 파일 하나가 아니라 추론 서버, 캐싱, 배치 처리, 하드웨어 메모리 구성의 합으로 결정된다는 점입니다.
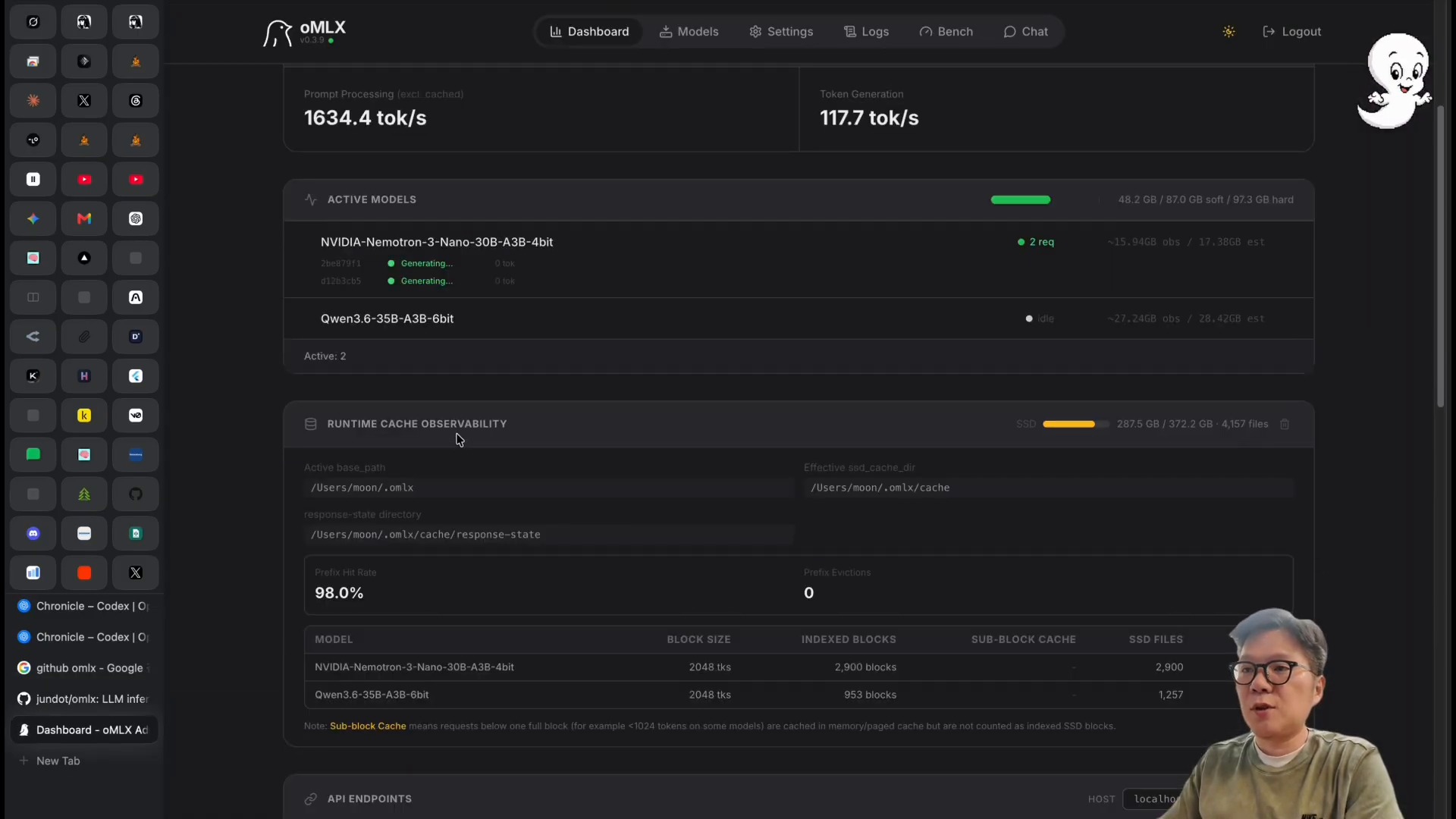
OMLX GitHub README는 이 도구를 Apple Silicon에 최적화된 LLM inference 서버로 설명합니다. 핵심 표현은 continuous batching과 tiered KV caching입니다. 쉽게 말하면 여러 요청을 효율적으로 처리하고, 반복되는 문맥 계산 비용을 줄여 체감 속도를 높이는 구조입니다.
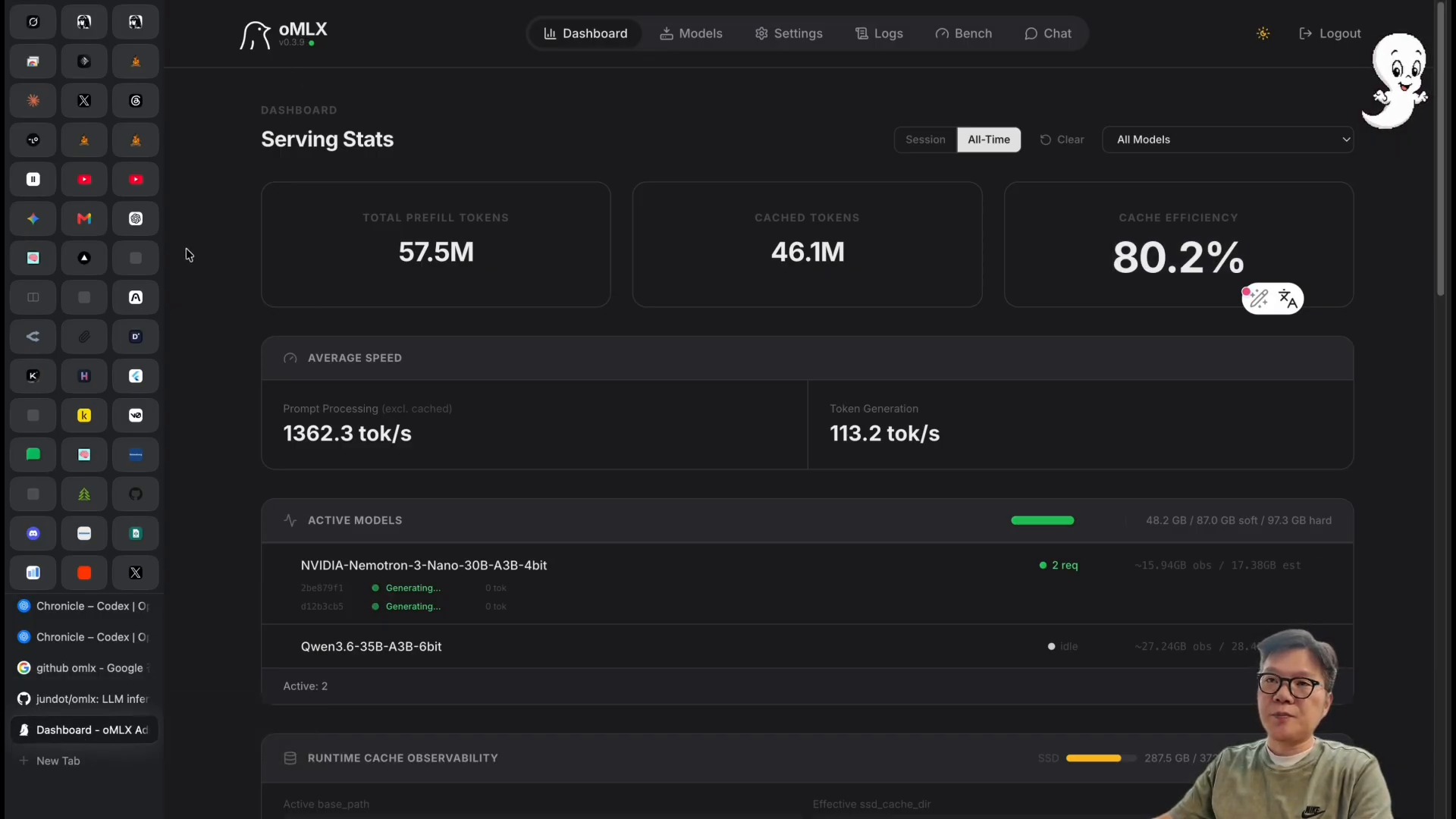
이 지점은 SGLang 로컬 LLM 서빙 엔진 글과도 이어집니다. 로컬 LLM을 제대로 쓰려면 모델 선택만큼이나 서빙 엔진, 컨텍스트 관리, 캐싱 전략이 더 봐야 합니다.
Claude Code와 로컬 모델: 빠르지만 검증은 별도다
영상 중반부에서는 omlx launch claude 흐름으로 Claude Code를 로컬 모델에 연결합니다. 이후 텍스트 작성과 테트리스 게임 생성 작업을 비교합니다. 진행자는 일부 작업에서 로컬 LLM이 더 빠르게 완료되는 모습을 보여주지만, 동시에 결과 품질은 별도로 확인해야 한다는 전제를 남깁니다.
이 대목에서 중요한 판단 기준은 “빠른가”보다 “어떤 작업을 맡겨도 되는가”입니다. 예를 들어 다음 작업은 로컬 모델에 먼저 맡겨볼 수 있습니다.
AI 코딩 흐름은 Headroom 토큰 다이어트 글과도 연결됩니다. 비용을 줄이는 방법은 모델을 로컬로 돌리는 것만이 아닙니다. 에이전트가 읽는 로그, 파일, 검색 결과를 줄이고 검증 루프를 설계하는 것도 같은 문제의 다른 해법입니다.
Hermes Agent와 로컬 LLM: 에이전트 운영의 다음 실험
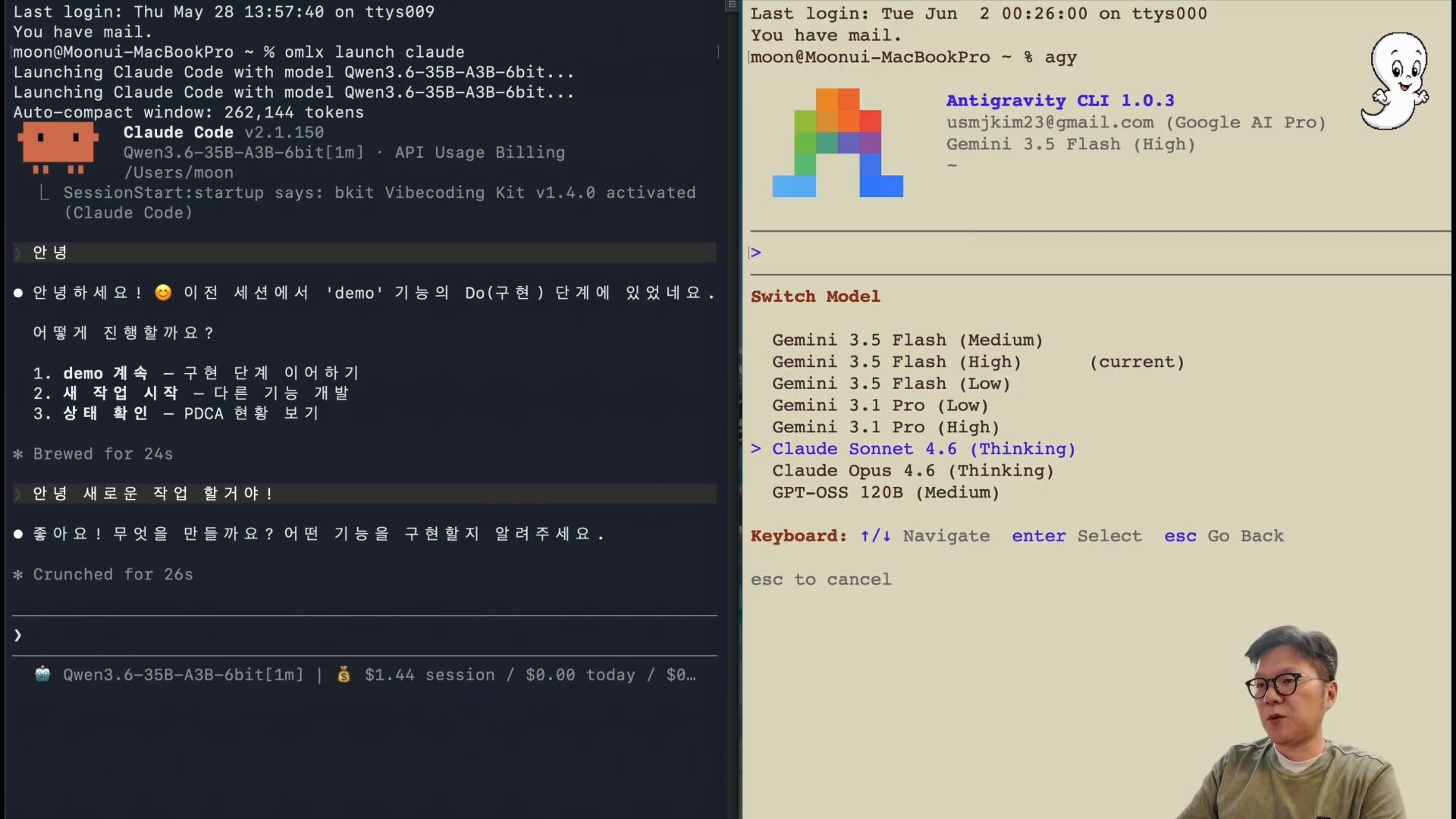
후반부에서 특히 흥미로운 부분은 Hermes Agent 연결입니다. 영상은 omlx launch hermes 흐름과 X Search 스킬 실행을 드러납니다. 로컬 모델이 단순 문장 생성기를 넘어 검색, 도구 호출, 요약, 산출물 생성을 담당하는 에이전트 런타임에 붙을 수 있음을 보여주는 장면입니다.
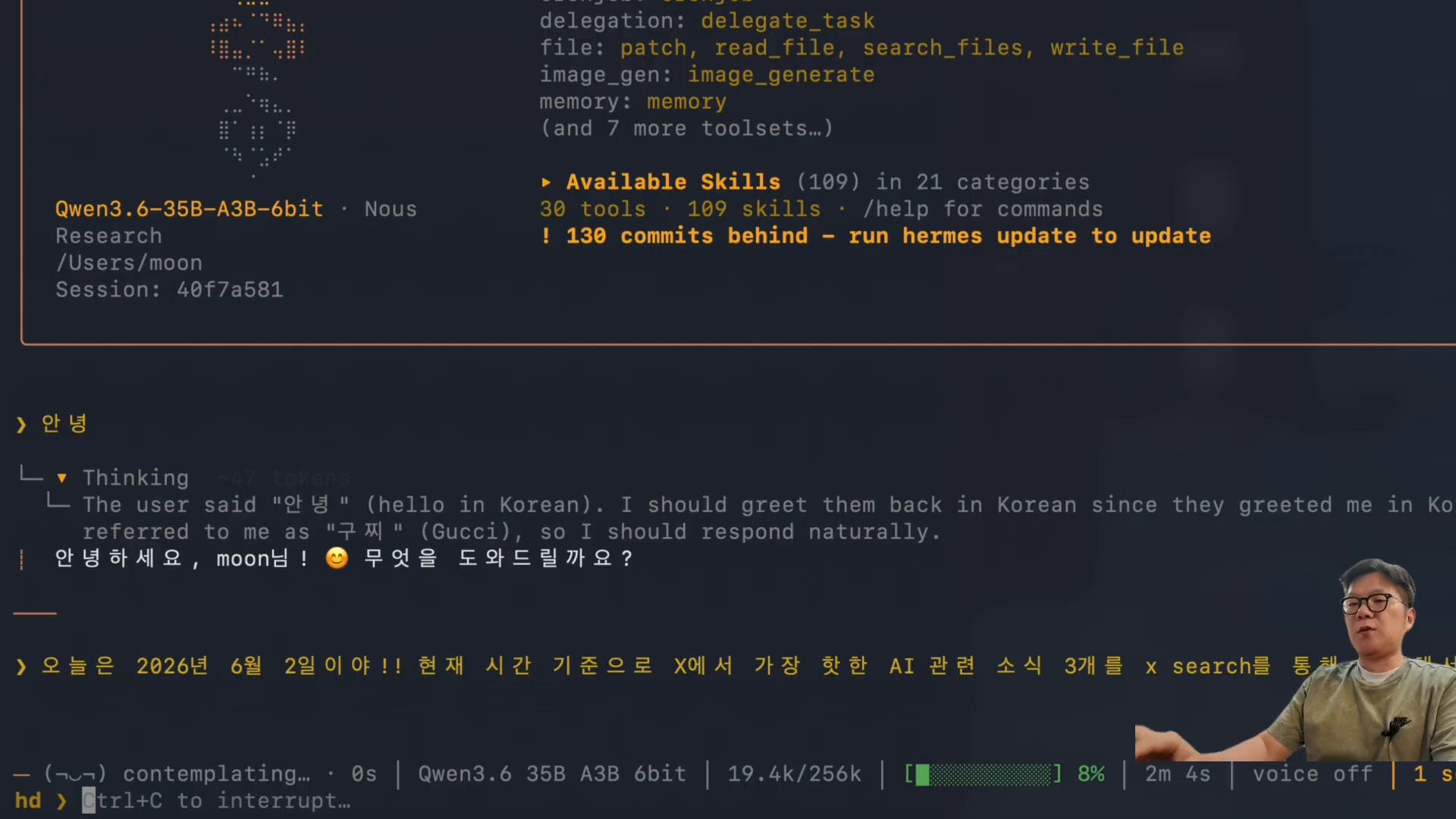
Hermes Agent는 터미널, 메시징 플랫폼, IDE에서 실행되는 오픈소스 AI 에이전트 프레임워크입니다. 도구 호출, 스킬, 메모리, 크론잡, 멀티 플랫폼 게이트웨이를 통해 작업을 실행합니다. 로컬 LLM을 여기에 연결할 수 있다면 다음과 같은 장점이 생깁니다.
- 개인 문서나 내부 로그를 외부 API로 덜 보내도 된다
- 반복적인 요약·분류·초안 작업의 토큰 비용을 낮출 수 있다
- 클라우드 모델 장애나 비용 제한이 있을 때 보조 경로가 생긴다
- 에이전트 실험을 더 많이 돌려볼 수 있다
주의할 점은 로컬 모델이 도구를 호출한다고 해서 곧바로 “믿고 맡길 수 있는 직원”이 되는 것은 아닙니다. AI 에이전트 시대의 개인 비서 글에서 다룬 것처럼, 실행형 AI일수록 권한, 검증, 로그, 되돌리기 설계가 더 봐야 합니다.
도입 전 체크리스트: 로컬 LLM은 이렇게 판단하자
로컬 LLM 도입 여부는 성능 수치 하나로 결정하면 위험합니다. 영상의 M5 Pro Max 128GB 환경은 강력한 상한선 사례에 가깝습니다. 일반적인 노트북이나 메모리가 작은 Mac에서는 같은 체감이 나오지 않을 수 있습니다.
도입 전에는 아래 순서로 판단하는 편이 좋습니다.
- 먼저 반복 업무를 고른다. 초안, 요약, 태깅, 코드 스캐폴딩처럼 실패 비용이 낮은 작업부터 시작한다.
- 같은 프롬프트를 클라우드 모델과 로컬 모델에 넣고 속도·품질·비용을 비교한다.
- 로컬 모델 산출물은 테스트, 링크 확인, 사실 검증을 자동화한다.
- 민감정보가 있는 작업과 외부 검색이 필요한 작업을 분리한다.
- 최종 판단이나 고위험 실행은 클라우드 상위 모델 또는 사람 검토를 남긴다.
이런 접근은 AI 네이티브 전환법 글에서 말한 “디지털 두뇌와 실행 에이전트의 분리”와도 맞닿아 있습니다. 로컬 LLM은 두뇌 전체를 대체하기보다, 자주 쓰는 일부 사고·실행 루프를 가까운 곳으로 가져오는 도구입니다.
결론: 로컬 LLM의 승부처는 대체가 아니라 배치다
이번 영상의 의미는 “로컬 LLM이 Claude나 GPT를 완전히 이겼다”가 아닙니다. 더 현실적인 결론은 로컬 LLM을 어디에 배치할지 정하는 단계가 왔다는 것입니다.
고사양 Mac과 OMLX 같은 서버가 있다면 로컬 LLM은 초안, 요약, 코드 생성, 개인 지식 검색, 에이전트 실험에서 충분히 실무적 선택지가 될 수 있습니다. 반대로 최신 정보 판단, 복잡한 추론, 높은 신뢰도가 필요한 업무는 여전히 클라우드 모델과 병행하는 편이 안전합니다.
결국 앞으로의 AI 업무 환경은 하나의 모델을 고르는 문제가 아닙니다. 로컬 모델, 클라우드 모델, 에이전트, 검색 도구, 지식 베이스를 어떤 기준으로 나눠 배치하느냐가 생산성을 가를 가능성이 높습니다.
FAQ
로컬 LLM이 Claude나 ChatGPT를 대체할 수 있나요?
일부 반복 업무에서는 대체하거나 보조할 수 있습니다. 하지만 복잡한 판단, 최신 정보 검증, 고위험 코드 변경은 클라우드 상위 모델이나 사람 검토와 병행하는 것이 안전합니다.
OMLX는 무엇인가요?
OMLX는 Apple Silicon에 최적화된 LLM inference 서버입니다. GitHub README 기준으로 continuous batching과 tiered KV caching을 강조하. macOS 메뉴바와 대시보드를 통해 로컬 모델 운영을 쉽게 하는 방향의 도구입니다.
M5 Pro Max 128GB가 아니어도 비슷한 결과가 나오나요?
같은 수준의 속도를 보장하기는 어렵습니다. 영상 결과는 고사양 Mac과 큰 메모리 환경의 영향을 크게 받습니다. 자신의 장비에서는 작은 모델과 반복 작업부터 테스트하는 편이 좋습니다.
Hermes Agent에 로컬 LLM을 연결하면 무엇이 좋아지나요?
검색, 파일 처리, 요약, 자동화 작업을 로컬 모델로 실험할 수 있습니다. 비용과 프라이버시 측면에서 장점이 있지만, 도구 실행 권한과 결과 검증 체계는 반드시 따로 설계해야 합니다.
로컬 LLM을 처음 도입한다면 어디서 시작해야 하나요?
개인 문서 요약, 회의록 정리, 코드 초안, 간단한 분류 작업처럼 실패 비용이 낮은 작업부터 시작하는 것이 좋습니다. 이후 클라우드 모델 결과와 비교해 품질 기준을 정하면 됩니다.
참고자료
이미지 출처: 본문에 사용된 캡쳐 이미지는 원본 YouTube 영상에서 리뷰·해설·교육 목적의 인용 이미지로 사용했습니다. 이미지 저작권은 원저작권자와 해당 채널에 있습니다.