
AI 에이전트를 쓰기 시작하면 가장 먼저 놀라는 것이 답변 품질이 아닐 수 있습니다. 더 현실적인 충격은 사용량과 비용입니다. 코딩 에이전트가 로그, 파일, 검색 결과, 대화 기록을 계속 읽으면 토큰은 빠르게 불어납니다.
Read in English: AI Token Diet: What Headroom Teaches About Cutting LLM Agent Costs
최근 The Register는 넷플릭스 시니어 엔지니어 Tejas Chopra가 만든 오픈소스 프로젝트 Headroom을 소개했습니다. 기사에 따르면 이 프로젝트는 Netflix의 공식 프로젝트는 아니지만, 여러 팀과 외부 프로젝트에서 사용되고 있습니다. 먼저 볼 부분은 간단합니다. LLM에 보내기 전에 불필요한 컨텍스트를 줄여 “토큰 다이어트”를 하자는 것입니다.
Headroom은 무엇인가

Headroom은 AI 에이전트가 LLM에 보내는 입력을 압축하는 컨텍스트 압축 계층입니다. GitHub 저장소 설명에 따르면 tool output, 로그, 파일, RAG chunk를 LLM에 도달하기 전에 줄이는 도구입니다.
Headroom은 하나의 프롬프트 압축 팁이 아닙니다. 라이브러리, 프록시, MCP 서버, 에이전트 wrapper 형태로 쓸 수 있는 개발자 도구에 가깝습니다. Claude Code, Codex, Cursor, Aider 같은 코딩 에이전트 앞단에 붙여 토큰 낭비를 줄이는 방식입니다.
중요한 점은 “모든 글자를 무조건 압축한다”가 아닙니다. Headroom은 입력의 종류를 보고 다른 압축 방식을 적용합니다. JSON은 JSON에 맞게, 코드는 코드 구조에 맞게, 일반 텍스트는 텍스트에 맞게 줄이는 식입니다.
왜 AI 에이전트 시대에 토큰 비용이 커지는가
챗봇을 쓸 때는 사용자가 질문을 입력하고 답을 받습니다. 하지만 AI 에이전트는 다릅니다. 에이전트는 파일을 읽고, 검색하고, 로그를 확인하고, 도구를 호출하고, 그 결과를 다시 LLM에 넣습니다.
문제는 이 과정에서 중복이 많이 생긴다는 점입니다. 같은 에러 로그가 여러 번 들어가고, 필요 없는 파일 내용이 함께 들어가며, RAG 검색 결과가 너무 넓게 붙습니다. 사람에게는 잡음처럼 보이는 정보도 토큰으로는 모두 비용이 됩니다.
The Register 기사에 따르면 Chopra는 Claude Sonnet 사용 중 $287 청구서를 보고 토큰 절감 문제에 관심을 갖게 됐습니다. 이후 많은 입력이 실제 추론에 꼭 필요한 정보가 아니라 반복·보일러플레이트·중복 데이터라는 점을 확인했다고 설명했습니다.
Headroom의 핵심 구조
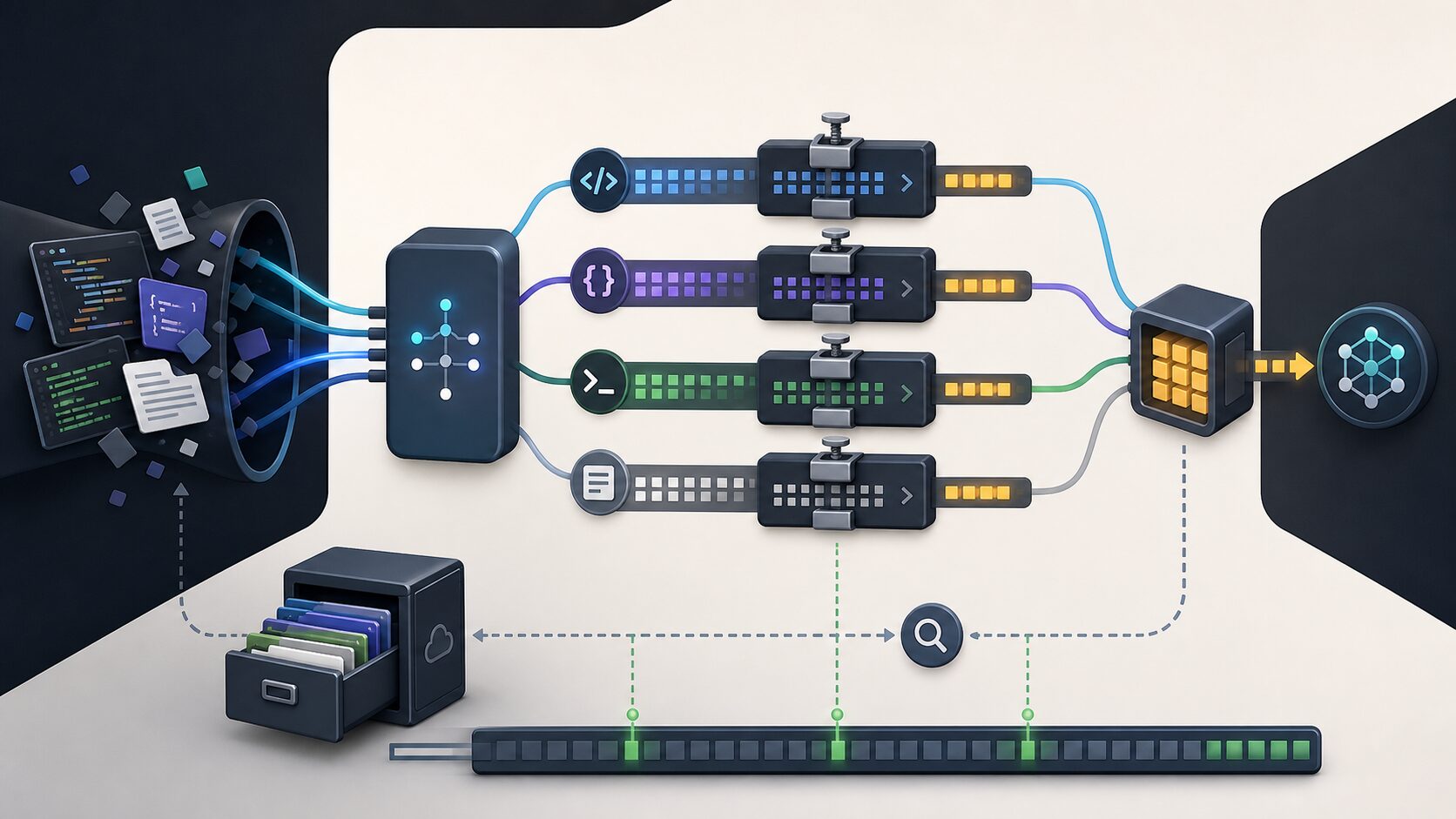
Headroom README는 구조를 CacheAligner, ContentRouter, CCR, SmartCrusher, CodeCompressor, Kompress-base 같은 구성으로 설명합니다. 이름은 복잡하지만 흐름은 실무적으로 이해할 수 있습니다.
첫째, ContentRouter는 입력의 종류를 구분합니다. 코드, JSON, 로그, 일반 텍스트를 같은 방식으로 줄이면 오류가 납니다. 그래서 먼저 내용의 성격을 판단합니다.
둘째, CodeCompressor와 SmartCrusher는 코드와 JSON처럼 구조가 중요한 데이터를 조심스럽게 줄입니다. 코드에서 식별자나 문법을 망가뜨리면 절감보다 손실이 커집니다.
셋째, CCR은 원본을 로컬에 보관하고 필요할 때 다시 가져오게 하는 방식입니다. 압축본만 보내되, 모델이 원문이 필요하다고 판단하면 retrieval 도구로 원본을 조회할 수 있게 합니다.
넷째, CacheAligner는 provider의 캐시가 깨지지 않도록 입력 prefix를 안정화하는 역할을 합니다. 단순 압축은 캐시 적중률을 낮춰 오히려 비용을 늘릴 수 있습니다. 이 지점이 Headroom이 단순 프롬프트 요약 도구와 다른 부분입니다.
숫자는 어떻게 봐야 할까
Headroom README는 실제 agent workload에서 60~95% fewer tokens를 내세웁니다. 예시로 code search, SRE incident debugging, GitHub issue triage, codebase exploration 같은 작업에서 큰 절감률을 보입니다.
주의할 점은 이 숫자는 그대로 모든 조직에 적용되는 보장값으로 보면 안 됩니다. 어떤 작업은 로그와 검색 결과가 많아 절감 여지가 큽니다. 반대로 짧은 질문이나 이미 잘 정리된 입력은 줄일 토큰이 많지 않습니다.
그래서 실무 판단 기준은 “얼마나 줄어든다고 홍보하는가”가 아닙니다. 우리 조직의 실제 agent workflow에서 입력 토큰, 출력 토큰, 지연 시간, 캐시 적중률, 실패율을 함께 측정해야 합니다.
토큰 다이어트가 필요한 팀의 신호
Headroom 같은 도구를 바로 도입해야 하는 팀은 몇 가지 신호가 있습니다.
- 코딩 에이전트가 큰 저장소를 반복해서 읽습니다.
- 로그와 테스트 결과가 매 요청마다 길게 붙습니다.
- RAG 검색 결과가 과도하게 많이 들어갑니다.
- 같은 시스템 프롬프트와 정책 문서가 계속 반복됩니다.
- 사용량 한도나 월 비용 때문에 AI 도구 활용이 멈춥니다.
이런 상황에서는 모델을 바꾸기 전에 컨텍스트 구조부터 봐야 합니다. 비싼 모델이 문제가 아니라, 비싼 모델에 불필요한 입력을 계속 보내는 구조가 문제일 수 있습니다.
조직이 배워야 할 5가지 교훈
첫째, AI 비용 최적화는 재무팀의 일이 아니라 엔지니어링 문제입니다. 비용은 토큰 구조, 도구 호출, 캐시 설계, RAG 품질에서 결정됩니다.
둘째, 프롬프트 압축은 마지막 단계입니다. 먼저 검색 결과를 줄이고, 중복을 제거하고, 필요한 파일만 읽게 해야 합니다. 원천에서 줄이지 못한 낭비를 문장 압축만으로 해결하기는 어렵습니다.
셋째, 압축은 품질 검증과 함께 가야 합니다. 토큰이 줄어도 답이 틀리면 실패입니다. Headroom이 benchmark와 재현 명령을 함께 제시하는 이유도 여기에 있습니다.
넷째, 캐시를 깨지 않는 설계가 더 봐야 합니다. 공급자의 prompt cache는 입력이 조금만 바뀌어도 효과가 떨어질 수 있습니다. 절감 도구가 캐시를 망가뜨리면 총비용은 오히려 늘어납니다.
다섯째, 원본 보존이 해야 합니다. AI가 압축된 정보만 보고 판단하면 중요한 맥락을 놓칠 수 있습니다. 필요할 때 원문을 다시 조회할 수 있는 구조가 안전합니다.
도입 전 체크리스트

Headroom이나 유사 도구를 검토한다면 다음 항목부터 체크해 두세요.
- 현재 agent 작업별 입력 토큰과 출력 토큰을 측정하고 있는가?
- RAG 검색 결과의 topK와 중복 제거 기준이 있는가?
- 로그·파일·테스트 결과를 통째로 넣고 있지는 않은가?
- 압축 전후 정답률과 작업 성공률을 비교할 수 있는가?
- 코드, JSON, 보안 정책, URL, 식별자를 안전하게 보호하는가?
- 캐시 적중률이 압축 후에도 유지되는가?
- 실패 시 압축을 끄고 재실행하는 fallback이 있는가?
함께 읽으면 좋은 글
- AI 네이티브 전환법: 디지털 두뇌와 AI 에이전트로 일하는 방식 바꾸기
- 하네스 엔지니어링이 온다: AI 에이전트를 제대로 일하게 만드는 법
- 에이전틱 엔지니어링: 안드레이 카파시가 말한 바이브 코딩 이후의 개발 방식
- AI 도구를 하나로 묶는 Agent OS 구축법: 7단계 블루프린트
결론: AI 비용은 사용량 문제가 아니라 설계 문제다
Headroom이 주는 시사점은 “토큰을 아껴 쓰자” 정도가 아닙니다. AI 에이전트가 조직의 일하는 방식 안으로 들어오면, 컨텍스트를 어떻게 수집하고 줄이고 보존하고 재사용할지가 핵심 역량이 됩니다.
앞으로 좋은 AI 시스템은 모델만 좋은 시스템이 아닙니다. 필요한 정보만 보내고, 중복을 줄이며, 캐시를 활용하고, 실패 시 원본으로 돌아갈 수 있는 시스템입니다. 토큰 다이어트는 비용 절감 기술이면서 동시에 AI 운영 설계의 출발점입니다.
FAQ
Headroom은 Netflix 공식 프로젝트인가요?
The Register 보도에 따르면 Headroom은 Netflix 공식 프로젝트가 아닙니다. 넷플릭스 시니어 엔지니어 Tejas Chopra가 만든 오픈소스 프로젝트이며, 여러 팀과 외부 프로젝트에서 사용되는 것으로 소개됐습니다.
Headroom은 프롬프트를 요약하는 도구인가요?
단순 요약 도구로 보기에는 좁습니다. Headroom은 로그, 파일, RAG 결과, tool output, 대화 기록을 LLM 호출 전에 줄이는 컨텍스트 압축 계층입니다. 라이브러리, 프록시, MCP 서버, 에이전트 wrapper 형태로 사용할 수 있습니다.
토큰을 줄이면 답변 품질이 떨어지지 않나요?
수 있습니다. 그래서 압축 전후의 작업 성공률, 정답률, 지연 시간, 캐시 적중률을 함께 봐야 합니다. 코드나 JSON처럼 구조가 중요한 데이터는 무리하게 압축하면 위험합니다.
어떤 조직에 먼저 필요할까요?
코딩 에이전트, RAG, 대규모 로그 분석, SRE incident 대응, 대형 코드베이스 탐색을 자주 하는 조직에 먼저 해야 합니다. 짧은 질의응답 위주의 팀이라면 효과가 제한적일 수 있습니다.