This English version is a fuller translation and adaptation of the original Korean article, “넷플릭스 개발자의 토큰 다이어트: Headroom이 보여준 AI 비용 절감법,” for global readers. The article discusses the importance of reducing token costs when using AI agents, and how the open-source project Headroom can help achieve this goal. As AI agents become more prevalent in various industries, the need to optimize their performance and reduce costs becomes increasingly important. One of the key challenges in using AI agents is the high cost of tokens, which can quickly add up and become a significant expense. In this article, we will explore the main arguments and findings of the original Korean article and provide a comprehensive overview of the topic.

Original Korean article: 넷플릭스 개발자의 토큰 다이어트: Headroom이 보여준 AI 비용 절감법
What is Headroom?
Headroom is a context compression layer that compresses the input sent to LLM (Large Language Models) by AI agents. According to the GitHub repository description, it is a tool that reduces tool output, logs, files, and RAG (Retrieval-Augmented Generation) chunks before they reach the LLM. Headroom is not just a simple prompt compression tip, but rather a developer tool that can be used in various forms, such as a library, proxy, MCP (Model-Parallel Computing) server, or agent wrapper. It can be used in front of coding agents like Claude Code, Codex, Cursor, and Aider to reduce token waste.
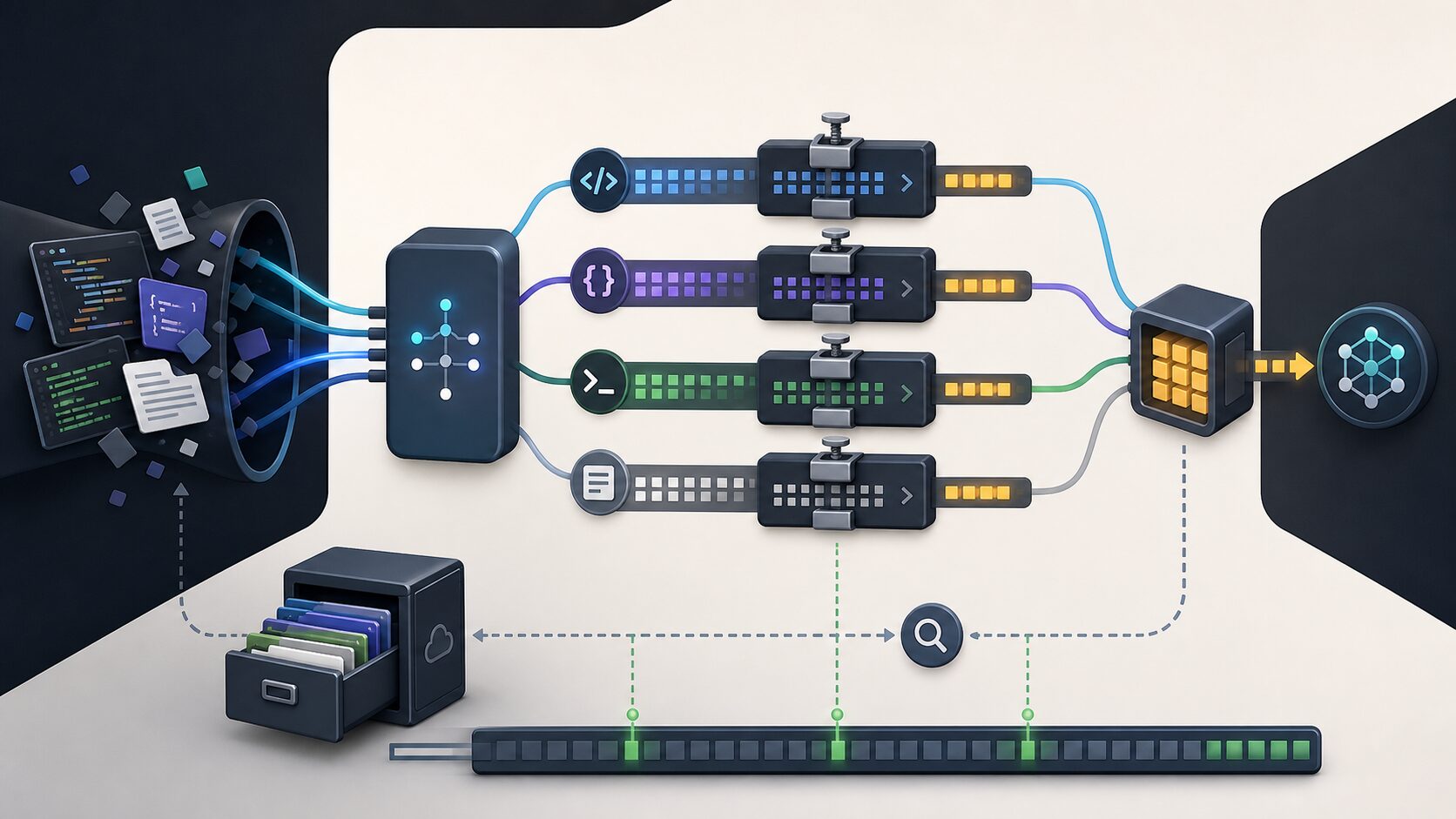
Why do AI agent costs increase?
When using chatbots, users input questions and receive answers. However, AI agents are different. They read files, search, check logs, call tools, and put the results back into the LLM. The problem is that this process creates a lot of duplication. The same error logs are entered multiple times, unnecessary file contents are included, and RAG search results are too broad. Even information that seems like noise to humans can incur token costs. According to The Register, Tejas Chopra, the creator of Headroom, became interested in token reduction after receiving a $287 bill while using Claude Sonnet. He then discovered that many inputs were not necessary for actual reasoning, but rather consisted of repetition, boilerplate, and duplicate data.
Headroom’s Core Structure
The Headroom README explains the structure as consisting of components like CacheAligner, ContentRouter, CCR (Context Compression and Retrieval), SmartCrusher, CodeCompressor, and Kompress-base. Although the names may seem complex, the flow can be understood in a practical sense. First, ContentRouter distinguishes the type of input. Reducing code, JSON, logs, and plain text in the same way can lead to errors, so it is essential to determine the nature of the content first. Second, CodeCompressor and SmartCrusher carefully reduce structured data like code and JSON. Reducing code can damage identifiers or grammar, leading to more loss than gain. Third, CCR stores the original content locally and retrieves it when necessary. It sends only the compressed version but allows the model to retrieve the original content if needed. Fourth, CacheAligner stabilizes the input prefix to prevent the provider’s cache from being broken. Simple compression can lower the cache hit rate, ultimately increasing costs. This is where Headroom differs from simple prompt summarization tools.

What do the numbers mean?
The Headroom README claims that it can reduce tokens by 60-95% in actual agent workloads. Examples include code search, SRE incident debugging, GitHub issue triage, and codebase exploration, which show significant reduction rates. However, it is essential to note that these numbers do not guarantee the same results for all organizations. Some tasks may have a lot of logs and search results, making them more prone to reduction. On the other hand, short questions or well-organized inputs may not have many tokens to reduce. Therefore, the practical judgment standard is not just about how much reduction is promised, but rather about measuring input tokens, output tokens, latency, cache hit rate, and failure rate in the actual agent workflow.
Signals that a team needs token diet
Teams that should consider introducing Headroom or similar tools are those that exhibit certain signals. These include: coding agents that repeatedly read large repositories, logs and test results that are attached to every request, RAG search results that are overly broad, system prompts and policy documents that are repeated continuously, and AI tool utilization that is halted due to usage limits or monthly costs. In such situations, it is essential to examine the context structure before changing the model. The problem may not be the expensive model itself, but rather the structure that continuously sends unnecessary inputs to the expensive model.
5 Lessons for Organizations
First, AI cost optimization is not just a financial issue, but an engineering problem. Costs are determined by token structure, tool calls, cache design, and RAG quality. Second, prompt compression is the last step. It is essential to reduce search results, remove duplicates, and read only necessary files before compressing sentences. It is challenging to solve waste that is not reduced at the source through sentence compression alone. Third, compression must be accompanied by quality verification. If the answer is incorrect, even if the tokens are reduced, it is a failure. This is why Headroom provides benchmarks and reproduction commands. Fourth, cache-preserving design is crucial. Provider prompt caches can be ineffective if the input changes slightly. If the reduction tool breaks the cache, the total cost may increase. Fifth, preserving the original content is essential. If AI only looks at compressed information, it may miss important context. Having a structure that can retrieve the original content when needed is safe.
Pre-Introduction Checklist
When reviewing Headroom or similar tools, check the following items first: Are you currently measuring input tokens and output tokens for each agent task? Do you have topK and duplicate removal criteria for RAG search results? Are you putting logs, files, and test results in their entirety? Can you compare the answer rate and task success rate before and after compression? Are you safely protecting code, JSON, security policies, URLs, and identifiers? Is the cache hit rate maintained after compression? Do you have a fallback to turn off compression and re-run in case of failure?
Conclusion: AI costs are a design problem, not a usage problem
The insight provided by Headroom is not just about reducing tokens, but about how AI agents fit into an organization’s workflow. When AI agents become part of the workflow, the key capability is how to collect, reduce, preserve, and reuse context. In the future, good AI systems will not just have good models, but will also be able to send only necessary information, reduce duplication, utilize caches, and return to the original content in case of failure. Token diet is not just a cost-reduction technique, but also the starting point for AI operation design.
Related Reading
Continue with these related Thinknote English articles in the Digital Transformation cluster.
- Thinknote English article
- Thinknote English article
- Thinknote English article
- Thinknote English article
- Thinknote English article
- Thinknote English article
FAQ
What is this article about?
This article explains a digital transformation, platform, market-structure, or technology-adoption topic with Korea-specific context and global implications.
How should I use this guide?
Use it to understand market signals and strategic patterns. Combine it with current market data before making business or investment decisions.
Where can I read the original Korean article?
The original Korean article is available here: AI Token Diet: What Headroom Teaches About Cutting LLM Agent Costs.