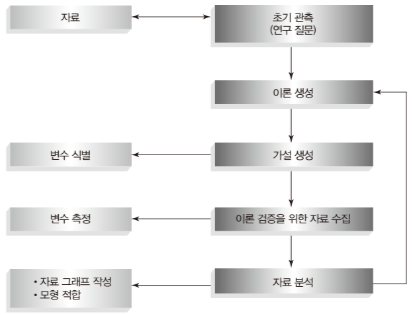
연구방법 (Research Method)은 연구자가 특정 연구 주제나 문제를 탐구하고, 데이터를 수집하고 분석하여 결론을 도출하는 체계적이고 조직적인 절차를 의미한다. 연구방법은 양적 연구와 질적 연구 등으로 나눌 수 있다.
연구방법은 학문 분야마다 다르며, 각 분야에서는 그 특성에 맞는 다양한 방법론과 도구들이 개발되어 사용되고 있다.
연구방법 R통계 학습은 분석 기법보다 연구 설계를 먼저 이해하는 데서 시작됩니다. 어떤 질문을 던지고, 어떤 자료를 모으며, 어떤 방식으로 결과를 해석할지에 따라 사용할 통계 방법이 달라집니다. 이 글은 양적연구와 질적연구, 횡단·종단 연구, 상관·실험 연구의 차이를 R통계 학습 흐름과 연결해 설명합니다.
Ⅰ. 양적연구 (Quantitative Research)
Ⅰ – 1. 종류 및 특징:
- 양적연구는 수치화된 데이터를 통해 현상을 분석하고 해석하는 연구 방법이다.
- 목적: 가설을 검증하고, 변수들 간의 관계를 명확하게 파악하며, 일반화를 통해 예측 모델을 구축하는 데 목적이 있다.
- 자료 수집 방법: 설문조사, 실험, 관찰 등의 방법을 통해 대규모 표본에서 데이터를 수집한다.
- 분석 방법: 통계적 기법과 수학적 모델을 활용하여 데이터 분석을 수행한다.
Ⅰ – 2. 활용 예시:
- 학생들의 학업 성취도를 평가하기 위해 전국적으로 실시되는 표준화된 시험 결과를 분석하는 연구.
- 특정 제품의 시장 점유율 변화와 소비자 만족도 간의 관계를 조사하는 마케팅 연구.
- 의료 분야에서 특정 약물의 효과를 검증하기 위해 임상시험 데이터를 분석하는 연구.
Ⅱ. 질적연구 (Qualitative Research)
Ⅱ – 1. 종류 및 특징:
- 질적연구는 비수치화된 데이터를 통해 인간 행동과 경험, 사회 현상을 심층적으로 이해하려는 연구 방법이다.
- 목적: 복잡한 현상이나 맥락에 대한 깊은 이해와 새로운 이론 생성에 중점을 둔다.
- 자료 수집 방법: 인터뷰, 참여 관찰, 문서 분석 등을 통해 소규모 표본에서 자료를 수집한다.
- 분석 방법: 주제별로 분류하고 해석하며, 내러티브나 사례 연구 방식으로 결과를 도출한다.
Ⅱ – 2. 활용 예시:
- 환자의 치료 경험과 감정을 심층 인터뷰를 통해 탐색하는 의료 사회학 연구.
- 특정 커뮤니티 내 문화와 전통이 어떻게 유지되고 변화하는지 참여 관찰을 통해 조사하는 인류학 연구.
- 기업 내 직원들의 조직문화와 직무 만족도를 탐색하기 위한 포커스 그룹 인터뷰 연구.

Ⅲ. 종단연구 (Longitudinal Study)
Ⅲ – 1. 종류 및 특징:
- 종단연구는 동일한 집단을 장기간에 걸쳐 반복적으로 조사하여 시간에 따른 변화를 추적하는 연구 방법이다.
- 목적: 시간의 흐름에 따라 변화하거나 발전하는 양상을 파악하고 원인과 결과 간의 관계를 명확히 규명하려고 한다.
- 자료 수집 시점: 여러 시점에서 반복적으로 데이터를 수집하여 추세와 변화를 추적한다.
- 장점과 한계: 개개인의 변화 과정을 상세히 파악할 수 있지만, 시간과 비용이 많이 든다.
Ⅲ – 2. 활용 예시:
- 어린이들의 성장 발달 과정을 유아기부터 청소년기까지 주기적으로 조사하는 성장 발달 연구.
- 특정 직업군의 경력 발전과 직무 만족도 변화를 장기간 추적하여 분석하는 인사관리 연구.
- 만성 질환 환자들을 대상으로 치료 효과와 생활 습관 변화를 추적 조사하여 장기적인 건강 결과를 평가하는 의료 연구.
Ⅳ. 상관연구 (Correlation Study)
Ⅳ – 1. 종류 및 특징:
- 상관연구는 두 변수 간의 관계를 확인하는 연구 방법입니다.
- 목적: 변수들 간의 연관성을 파악하고, 한 변수의 변화가 다른 변수에 어떤 영향을 미치는지를 알아내기 위함이다.
- 결과 해석: 상관계수(correlation coefficient)를 통해 두 변수 간의 관계 강도와 방향을 측정한다. 상관계수는 -1에서 +1까지 값을 가지며, +1은 완전한 양의 상관, -1은 완전한 음의 상관을 의미한다.
- 인과성: 상관연구는 인과성을 증명하지 않으며, 단지 변수가 함께 변화하는지를 보여준다.
Ⅳ – 2. 활용 예시:
- 학생들의 공부 시간과 성적 간의 관계를 조사하는 연구.
- 흡연량과 폐암 발병률 간의 관계를 분석하는 연구.
- 소득 수준과 행복 지수 사이의 연관성을 탐색하는 연구.
Ⅴ. 횡단연구 (Cross-sectional Study)
Ⅴ – 1. 종류 및 특징:
- 횡단면연구는 특정 시점에서 하나 이상의 특성을 가진 집단을 조사하여 자료를 수집하는 연구 방법이다.
- 목적: 특정 시점에서 다양한 변수들 간의 상태나 분포를 파악하기 위함이다.
- 자료 수집 시점: 단일 시점에서 데이터를 수집하므로 시간적 변화나 추세는 반영되지 않는다.
- 비교 용이성: 다양한 그룹(예: 연령대별, 성별 등)을 비교하기에 용이한다.
Ⅴ – 2. 활용 예시:
- 특정 연령대 인구의 건강 상태와 생활 습관을 조사하는 연구.
- 한 국가 내 다양한 지역 주민들의 교육 수준과 소득 수준 간 차이를 분석하는 연구.
- 특정 질병 유병률을 파악하기 위해 여러 인구 집단을 동시에 조사하는 연구.
Ⅵ. 행동실험법 (Behavioral Experimentation)
Ⅵ – 1. 종류 및 특징:
- 행동실험법은 실험 환경에서 피실험자의 행동 반응을 유도하고 관찰하여 심리학이나 인간 행동 패턴을 이해하려는 연구 방법이다.
- 목적: 특정 자극이나 조건 하에서 인간 또는 동물의 행동 반응을 측정하고 이를 토대로 이론을 검증하거나 새로운 발견을 하는데 있다.
- 자료 수집 방법: 실험 설계에 따라 제어된 환경에서 실험 참가자들에게 다양한 자극이나 과제를 제공하고 그 반응을 기록한다.
- 분석 방법: 실험 결과를 통계적으로 분석하여 가설 검증이나 이론 도출에 사용한다.
Ⅵ – 2. 활용 예시:
- 특정 광고 메시지가 소비자의 구매 의도에 미치는 영향을 확인하기 위한 마케팅 실험.
- 스트레스가 작업 수행 능력에 미치는 영향을 평가하기 위한 심리학 실험.
- 신경 과학 분야에서는 뇌 활동과 행동 간의 관계를 이해하기 위해 전자기파 등 다양한 기술로 뇌 활동을 측정하면서 행동 반응을 기록하는 실험.
함께 읽으면 좋은 글
핵심 확인 체크리스트
- 연구 목적이 탐색·설명·검증 중 어디에 가까운가?
- 양적 자료와 질적 자료 중 무엇이 필요한가?
- 횡단 자료와 종단 자료 중 어떤 설계가 맞는가?
- 상관관계와 인과관계를 구분하고 있는가?
함께 읽으면 좋은 R통계 글
- 연구란 무엇인가: R통계 입문을 위한 연구 개념 정리
- 변수와 측정 R통계: 독립변수·종속변수와 측정 수준 이해
- 측정오차 R통계: 무작위 오차와 체계적 오차 쉽게 이해하기
- 타당성·신뢰성 R통계: 좋은 측정도구를 판단하는 기준
FAQ
연구방법을 R통계 전에 배워야 하는 이유는 무엇인가요?
R은 분석을 실행하는 도구이고 연구방법은 무엇을 왜 분석할지 정하는 틀입니다. 연구 설계가 분명해야 적절한 통계 기법과 R 함수를 선택할 수 있습니다.
양적연구와 질적연구는 어떻게 다르나요?
양적연구는 숫자로 측정 가능한 자료를 분석해 패턴이나 관계를 확인합니다. 질적연구는 인터뷰, 관찰, 문서처럼 의미와 맥락을 깊게 해석하는 데 초점을 둡니다.
상관연구와 실험연구는 언제 구분하나요?
두 변수의 관련성을 확인하려면 상관연구가 적합하고, 특정 처치가 결과에 영향을 주는지 보려면 실험연구가 해야 합니다. 인과관계를 주장하려면 연구 설계가 더 엄격해야 합니다.