AI 리서치 도구는 많아졌습니다. 문제는 결과가 흩어진다는 점입니다. NotebookLM에서 정리한 내용, 웹 검색 기반 리포트, AI CLI가 만든 요약, 그리고 내가 실제로 쓰는 노트가 따로 놀면 다시 붙이는 시간이 꽤 듭니다.
이번 영상에서 소개된 ReallyGood Research는 그 간격을 줄이려는 Obsidian 플러그인입니다. 질문 하나로 NotebookLM MCP와 Tavily 리서치를 실행하고, 결과를 Markdown과 HTML 리포트로 Vault 안에 저장하는 방식입니다. 핵심은 “검색을 잘하는 도구”가 아니라 “리서치 결과가 내 지식 작업 흐름 안에 남는 구조”입니다.
Read in English: Obsidian Deep Research Automation: How to Use NotebookLM and Tavily Together
영상에서 보여준 핵심 흐름
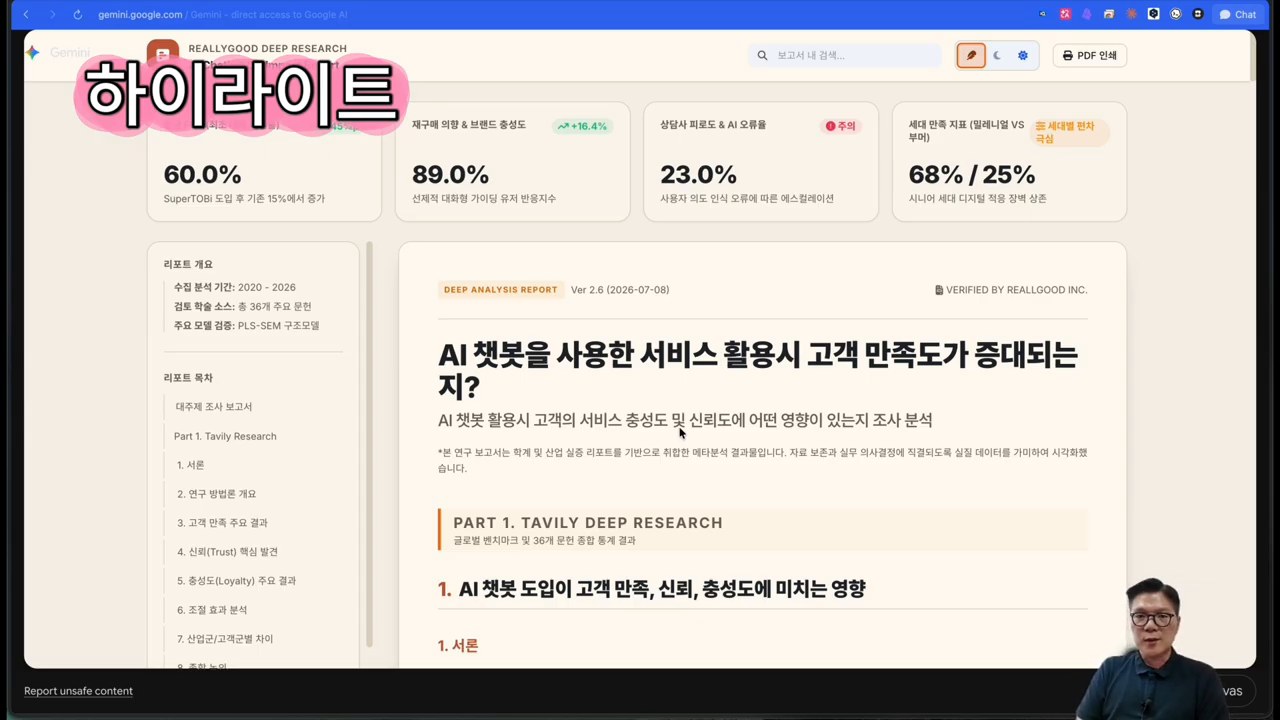
영상은 완성된 리포트 화면에서 시작합니다. 브라우저로 열린 HTML 리포트를 확인하고, Gemini Canvas 공유 링크로 확장하는 장면도 먼저 보여줍니다. 그래서 이 플러그인의 목적이 분명해집니다. 단순 검색이 아니라, 공유 가능한 리서치 산출물을 만드는 것입니다.
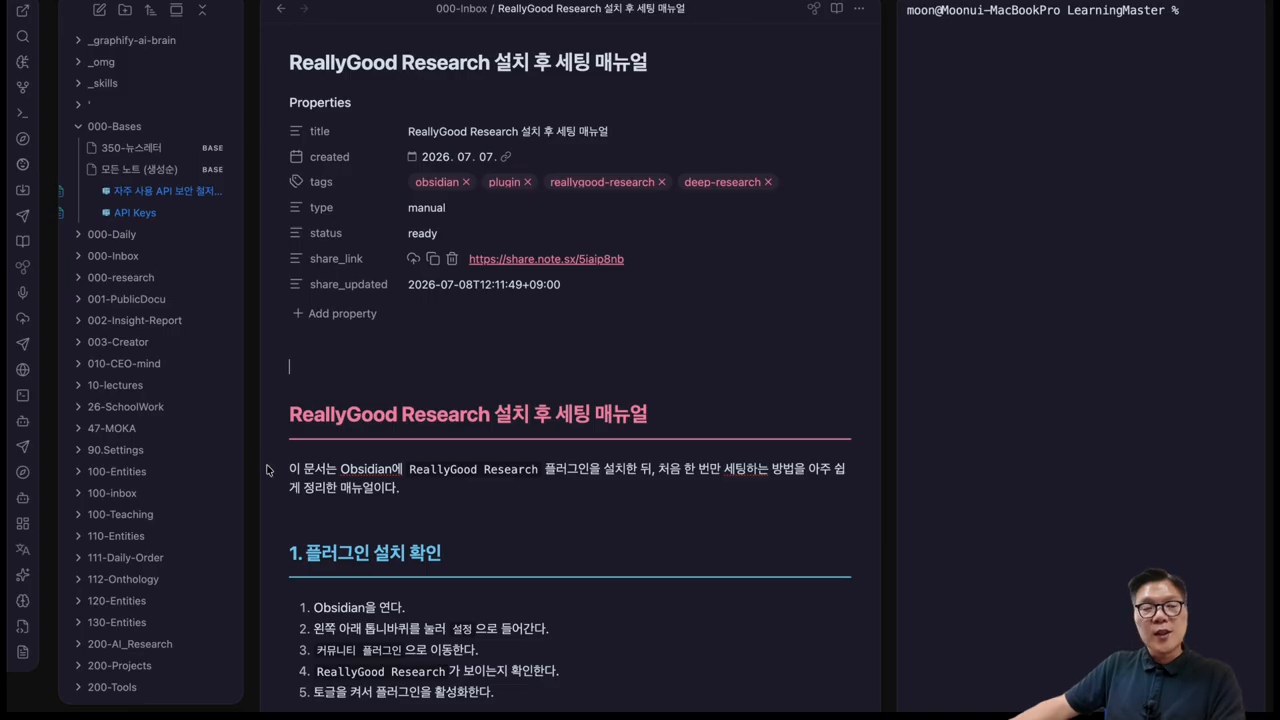
그다음 진행자는 Obsidian 안에서 플러그인을 설치하는 과정을 설명합니다. 커뮤니티 플러그인에서 ReallyGood Research를 검색하고 설치한 뒤, 왼쪽 패널에서 리서치 콘솔을 여는 흐름입니다. 별도 BRAT 설치 없이 커뮤니티 플러그인으로 접근할 수 있다는 점도 영상에서 강조됩니다.
NotebookLM과 Tavily를 왜 함께 쓰나
Tavily는 웹 검색과 리서치 API에 강점이 있습니다. 공개 웹에서 자료를 찾고, 주제별 리포트를 생성하는 데 적합합니다. 반면 NotebookLM은 사용자가 넣은 소스 기반으로 답을 구성하는 데 장점이 있습니다. 두 도구를 함께 쓰면 “웹에서 넓게 찾기”와 “소스 기반으로 다시 검토하기”를 분리할 수 있습니다.
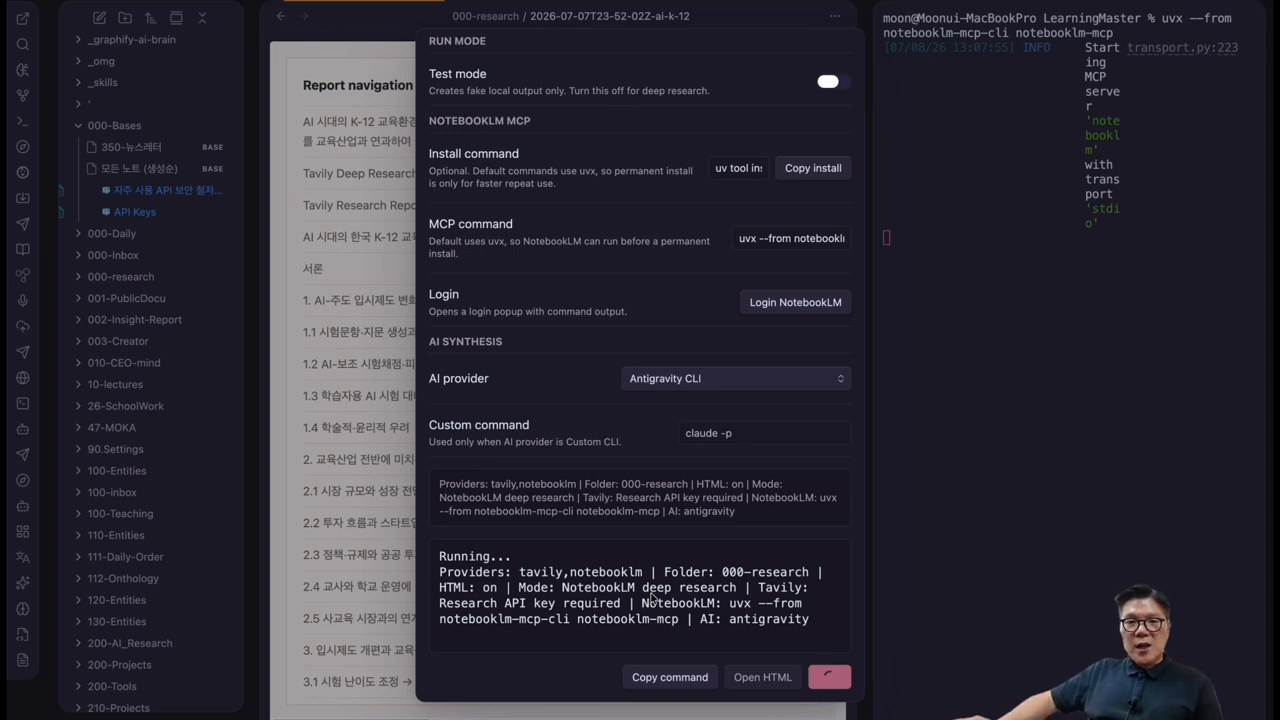
ReallyGood Research는 이 둘을 Provider로 연결합니다. 영상에서는 Tavily API 키를 넣고, NotebookLM MCP를 설치한 뒤 로그인하는 과정을 보여줍니다. 이후 AI CLI Provider로 Antigravity를 선택해 실행 환경을 맞춥니다. Claude Code, Codex, Gemini 같은 CLI를 고를 수 있다는 설명도 나옵니다.
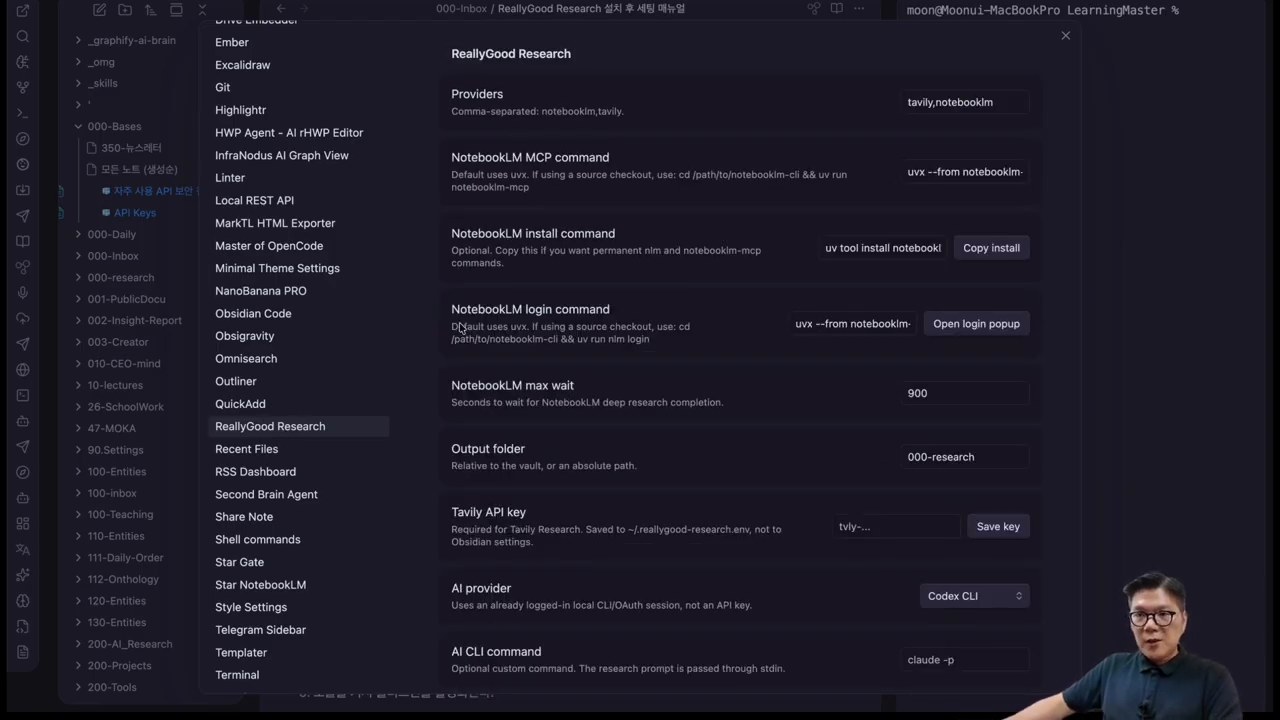
실제 사용 장면: 질문 하나가 두 개의 리포트로 바뀐다
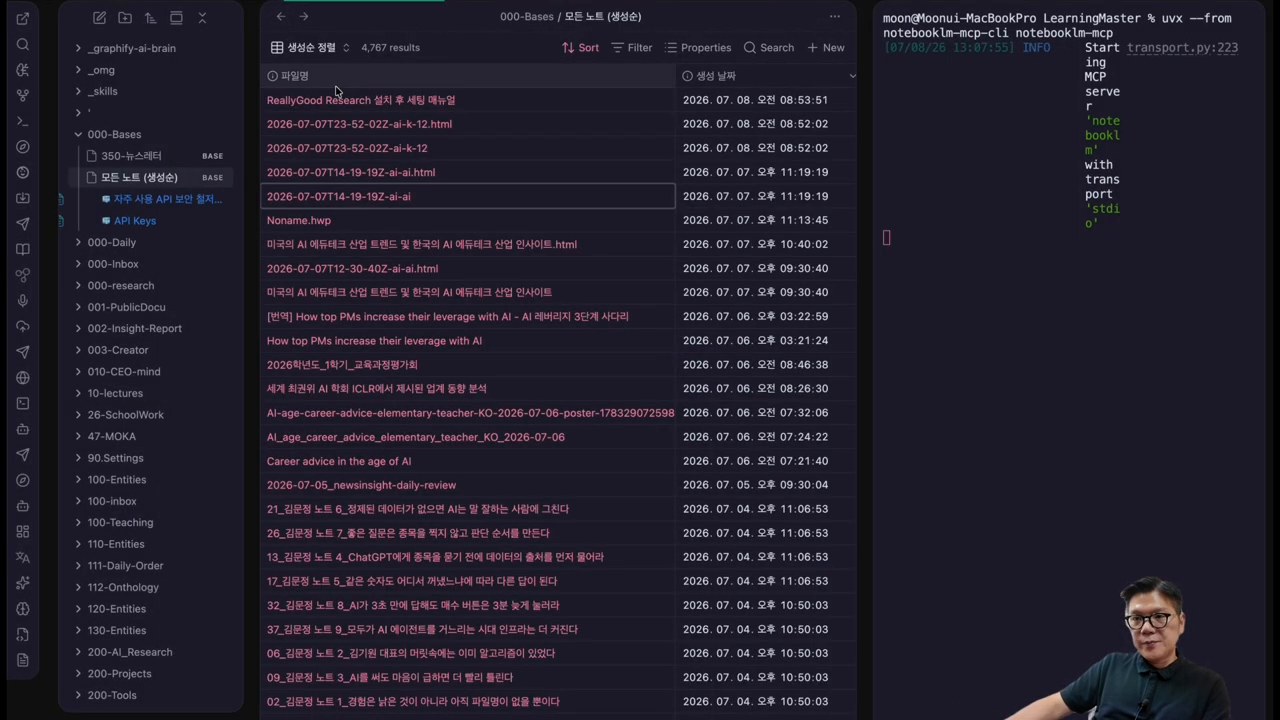
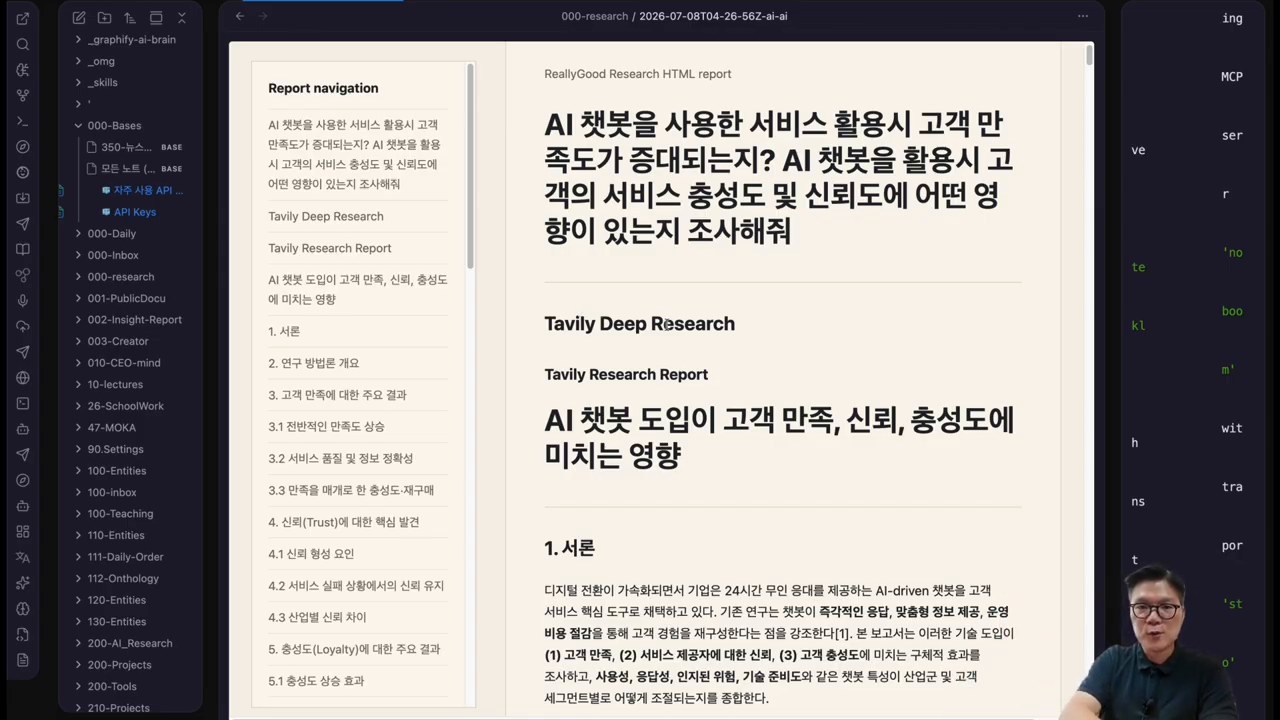
시연 질문은 “AI 챗봇을 사용한 서비스 활용이 고객 만족도, 충성도, 신뢰도에 어떤 영향을 미치는가”에 가깝습니다. 사용자가 질문을 입력하고 Start를 누르면, 플러그인은 Tavily 리서치와 NotebookLM 리서치를 각각 실행합니다.
중요한 장면은 결과 확인입니다. 하나의 질문에서 Tavily 기반 딥리서치 리포트와 NotebookLM 기반 리서치 결과가 따로 생성됩니다. 사용자는 둘을 비교하면서 근거가 충분한지, 관점이 한쪽으로 치우치지 않았는지 확인할 수 있습니다.
이 방식이 지식 작업에 주는 의미
이 플러그인의 장점은 자동화 그 자체보다 작업 위치에 있습니다. 리서치 결과가 Obsidian Vault 안에 저장되면, 이후 글쓰기·보고서·강의안·제안서로 이어가기 쉽습니다. 검색 결과를 다시 찾지 않아도 되고, HTML 리포트로 빠르게 공유할 수도 있습니다.
다만 확인할 점도 있습니다. Tavily API 키와 NotebookLM 로그인, 로컬 MCP 실행, AI CLI 권한이 필요합니다. 회사 자료나 민감한 고객 데이터를 넣을 때는 어떤 Provider로 정보가 전달되는지 먼저 봐야 합니다. 자동화가 편해질수록 로그, 출처, 계정 권한을 함께 관리해야 합니다.
도입 전에 확인할 체크리스트
- Obsidian을 실제 지식 저장소로 쓰고 있는가?
- Tavily API 키와 사용량 한도를 관리할 수 있는가?
- NotebookLM MCP 설치와 Google 로그인을 안전하게 처리할 수 있는가?
- 리서치 결과를 바로 글쓰기나 보고서로 이어갈 업무가 있는가?
- 자동 생성 결과를 검증할 기준과 출처 확인 습관이 있는가?
이 다섯 가지가 맞으면 테스트해 볼 만합니다. 반대로 단발성 검색만 필요하다면 과한 구성일 수 있습니다. ReallyGood Research는 검색 도구라기보다, Obsidian을 리서치 작업대처럼 쓰는 사람에게 더 잘 맞습니다.
함께 읽으면 좋은 글
- AI-Native Workflows: How to Rebuild Work Around a Digital Brain and AI Agents
- AI Second Brain: Building a Personal Knowledge System for AI Agents
- Antigravity CLI and Obsidian Automation: Turning Notes Into an AI Work Hub
- AI 코딩의 본질은 모델이 아니라 하네스다
FAQ
ReallyGood Research는 무엇인가요?
Obsidian에서 NotebookLM MCP와 Tavily 기반 딥리서치를 실행하고, 결과를 Markdown과 HTML 리포트로 저장하는 플러그인입니다. 영상 기준으로는 커뮤니티 플러그인 설치와 Provider 설정 흐름이 소개됩니다.
Tavily와 NotebookLM을 동시에 쓰는 이유는 무엇인가요?
Tavily는 웹 기반 리서치에 강하고, NotebookLM은 사용자가 제공한 소스 기반 검토에 강합니다. 둘을 함께 쓰면 넓은 탐색과 소스 기반 확인을 나눠 볼 수 있습니다.
Obsidian을 쓰지 않아도 필요한 도구인가요?
Obsidian을 중심 지식 저장소로 쓰지 않는다면 장점이 줄어듭니다. 이 플러그인은 결과를 Vault 안에 저장하고 다시 활용하는 흐름에 초점이 있습니다.
업무 자료를 넣어도 안전한가요?
도구 자체보다 Provider 설정이 중요합니다. Tavily, NotebookLM, AI CLI로 어떤 데이터가 전달되는지 확인해야 합니다. 민감한 자료는 조직 보안 기준에 맞춰 별도로 검토하는 것이 좋습니다.
이 플러그인은 누구에게 가장 잘 맞나요?
AI 리서치를 자주 하고, 결과를 글·보고서·강의안·제안서로 다시 쓰는 사람에게 잘 맞습니다. 특히 Obsidian을 세컨드 브레인이나 업무 지식 허브로 쓰는 사용자에게 유용합니다.