
This fuller English adaptation follows the Korean source on SGLang as a local LLM serving engine. The article’s question is practical: after trying Ollama for easy local use and vLLM for high-throughput serving, when should teams consider SGLang?
Original Korean article: SGLang 로컬 LLM 서빙 엔진, Ollama·vLLM 다음 선택지가 될까?
Why SGLang Is Getting Attention as a Local LLM Serving Engine
Closer to a service engine than a simple runner
Ollama made local model testing convenient. But production-like serving has different requirements: concurrency, latency, throughput, batching, caching, observability, and API stability. SGLang belongs to this service-oriented conversation. It is designed for structured generation workflows and efficient serving rather than only one-person experimentation.
Ecosystem signals are hard to ignore
The source article notes that ecosystem momentum matters. GitHub activity, benchmark discussions, model support, developer adoption, and integration examples all influence whether a serving engine becomes a serious option. SGLang is drawing attention because it addresses real bottlenecks in repeated LLM requests.
Core Principle: What RadixAttention Reduces
Common prompts do not need to be recalculated
RadixAttention is the key concept highlighted in the Korean article. Many LLM services repeatedly send prompts that share the same prefix: system instructions, policy text, examples, retrieved documents, tool descriptions, or conversation history. If the engine can reuse shared computation, it can reduce waste.
Why this matters for RAG and agent services
In RAG systems and agent workflows, repeated context is common. Many users may ask different questions over the same documents, or an agent may run multiple steps with the same tool instructions. Prefix reuse can improve throughput and latency when the workload matches the pattern.
How to Read Ollama, vLLM, and SGLang Comparisons
Benchmarks are strong, but conditions matter
The source article warns against reading benchmark numbers blindly. Performance depends on model size, GPU type, batch size, context length, request pattern, quantization, and serving configuration. A chart that favors one engine under one workload may not apply to another team’s service.
vLLM’s strengths remain important
vLLM remains a powerful and widely adopted serving option. Its ecosystem, PagedAttention, OpenAI-compatible APIs, and production experience make it a default candidate for many teams. SGLang should be evaluated against vLLM using the team’s own traffic pattern, not only public claims.
Decision Criteria by Situation
For personal tests, Ollama is still convenient
If the goal is to download a model and test prompts locally, Ollama remains the easiest starting point. It is simple, friendly, and good for learning. A developer experimenting on a laptop may not need a full serving engine.
For general service serving, start by reviewing vLLM
If the goal is a service API with multiple users, vLLM is often the first serious option to evaluate because of its maturity and ecosystem. Teams should measure throughput, latency, memory use, and operational complexity.
For repeated-context high-volume requests, evaluate SGLang
SGLang becomes especially interesting when requests share long prefixes or when agent/RAG workflows repeatedly reuse context. In those cases, RadixAttention and structured generation features may provide meaningful advantages.
Pre-Adoption Checklist
Look at tail latency, not only averages
Average latency can hide user pain. Teams should measure p95 and p99 latency, cold starts, long-context behavior, concurrency, error recovery, logging, deployment complexity, and compatibility with existing clients.
- Test with your own prompts, documents, and traffic shape.
- Compare GPU memory use under realistic concurrency.
- Check model support and OpenAI-compatible API behavior.
- Monitor tail latency and failed generations.
- Plan rollback to a known engine if production behavior differs from tests.
Conclusion: SGLang Is a Candidate for Service-Style Local LLMs
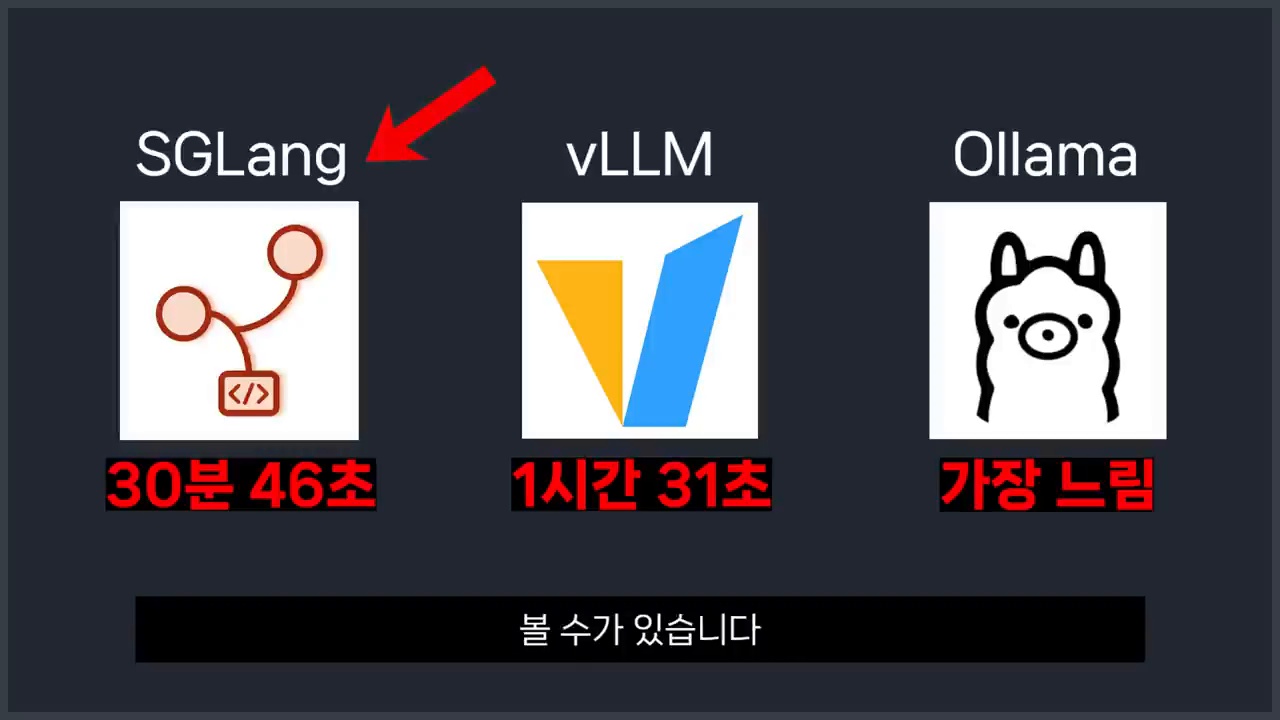
The article’s conclusion is balanced. SGLang is not automatically the replacement for Ollama or vLLM. It is a strong candidate when local LLM work moves from simple testing to repeated, service-style generation where caching and structured workflows matter.
For many teams, the best decision is staged. Use Ollama to learn the model, test vLLM when service traffic appears, and benchmark SGLang when repeated context, RAG, or agent chains become a real cost. The right engine is the one that fits the workload you can measure.
Related Reading
Continue with these related Thinknote English articles in the Digital Transformation cluster.
- Thinknote English article
- Thinknote English article
- Thinknote English article
- Thinknote English article
- Thinknote English article
- Thinknote English article
FAQ
What is this article about?
This article explains a digital transformation, platform, market-structure, or technology-adoption topic with Korea-specific context and global implications.
How should I use this guide?
Use it to understand market signals and strategic patterns. Combine it with current market data before making business or investment decisions.
Where can I read the original Korean article?
The original Korean article is available here: SGLang for Local LLM Serving: Is It the Next Step After Ollama and vLLM?.