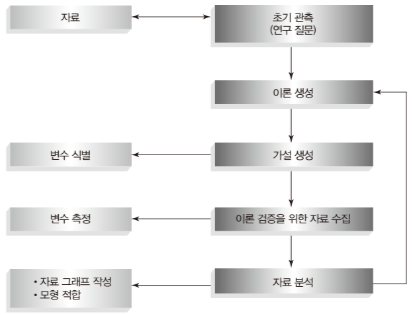
가설을 검증하기 위해서는 데이터를 정확하게 측정하고 분석하는 것이 중요하다. 하지만 측정 과정에서는 종종 측정오차가 발생한다. 측정오차는 우리가 실제로 측정하려는 값과 실제 측정된 값 사이의 차이를 의미한다.
측정오차 R통계 개념은 연구 결과의 신뢰성을 판단할 때 반드시 해야 합니다. 같은 대상을 측정해도 도구, 환경, 응답자 상태에 따라 값이 달라질 수 있고, 이 차이가 분석 결과에 영향을 줍니다. 이 글은 무작위 오차와 체계적 오차의 차이, 오차를 줄이는 기본 방법을 정리합니다.
이러한 오차는 결과 해석 및 결론 도출에 영향을 미칠 수 있으므로, 가설 검증에서 매우 중요한 요소이다.
측정오차를 최소화하고 통제하기 위해 실험 설계를 신중히 하고, 기기를 정기적으로 캘리브레이션하며, 반복적인 측정을 통해 무작위 오차를 평균화하고 체계적인 원인을 식별하여 교정해야 한다.
측정오차는 일반적으로 체계적 오차(systematic error)와 무작위 오차(random error)로 구분된다.

Ⅰ. 체계적 오차 (Systematic Error)
체계적 오차는 일관되게 특정 방향으로 발생하는 오차로, 반복적인 측정에서도 동일한 패턴을 보인다. 이는 반복 측정을 하더라도 동일한 방식으로 영향을 미치기 때문에, 평균을 내어도 사라지지 않습니다. 이러한 오차는 주로 측정 기기의 결함, 환경 조건의 변화, 또는 실험 방법 자체의 문제 등으로 인해 발생한다.
- 예측 가능성: 체계적 오차는 일정한 패턴을 가지므로 예측이 가능하다.
- 수정 가능성: 일단 원인을 파악하면 수정이 가능하다.
Ⅰ – 1. 체계적 오차의 유형
- 기기 오차(Instrumental Error):
측정 장비 자체의 결함이나 불완전함으로 인해 발생하는 오차다. 예를 들어, 저울이 일정량 만큼 항상 더 높은 값을 나타내거나 온도계가 실제 온도보다 낮은 값을 지속적으로 표시하는 경우가 이에 해당한다. - 환경적 요인(Environmental Factors):
환경 조건의 변화나 특정 환경 조건이 지속적으로 영향을 미칠 때 발생한다. 예를 들어, 온도나 습도의 변화가 측정 기기에 영향을 주거나 전자기 간섭 등이 있을 수 있다. - 절차 및 방법상의 오류(Procedural or Methodological Errors):
실험이나 측정 방법 자체의 문제로 인해 발생하는 오차다. 예를 들어, 샘플을 채취하는 방법이 일관되지 않거나 특정 실험 절차가 잘못 설정된 경우에 발생된다 - 인간의 오류(Human Error):
측정을 수행하는 사람이 일관되게 동일한 방식으로 잘못된 조작을 하거나 기록하는 경우이다. 이는 주로 훈련 부족이나 부주의로 인해 발생할 수 있다. - 교란 변수(Confounding Variables):
실험 설계에서 통제되지 않은 변수들이 결과에 영향을 미치는 경우이다. 이는 특히 사회과학 연구나 생명과학 연구에서 자주 발생할 수 있다.
Ⅰ – 2. 체계적 오차 최소화 전략
체계적 오차는 그 특성상 탐지하고 교정하기 어렵습니다. 그렇기 때문에 이를 최소화하기 위한 여러 가지 전략이 필요하다:
- 장비 검교정(Calibration of Instruments):
주기적으로 장비를 검교정하여 정확성을 유지한다. - 표준화(Standardization):
실험 및 측정 절차를 표준화하여 동일한 조건 하에서 수행될 수 있도록 한다. - 환경 통제(Control of Environmental Conditions):
가능한 한 환경 요인을 일정하게 유지하거나 통제한다. - 훈련 및 교육(Training and Education):
측정을 수행하는 사람들에게 충분한 훈련과 교육을 제공하여 인간의 실수를 줄인다. - 블라인드 테스트(Blind Testing):
연구자가 결과에 대해 선입견을 갖지 않도록 블라인드 테스트 기법을 활용할 수 있다.
체계적 오차를 줄이는 것은 연구와 실험 결과의 신뢰성을 높이는 데 매우 중요하다. 이를 위해 다양한 방법들을 활용하여 최대한 정확하고 일관된 데이터를 얻는 것이 중요하다.
Ⅱ. 무작위 오차 (Random Error)
무작위 오차는 측정 과정에서 불가피하게 발생하는 예측 불가능한 오차로, 각 측정마다 다른 크기와 방향으로 나타난다. 이러한 오차는 반복 측정을 통해 평균화되면 사라지거나 최소화될 수 있다. 주로 환경의 미세한 변화, 실험 조건의 미세한 변동, 또는 자연적인 요인 등으로 인해 발생한다.
- 예측 가능성: 무작위 오차는 예측이 불가능하며, 일정한 패턴을 보이지 않다.
- 수정 가능성: 반복 측정을 통해 평균값을 구하면 무작위 오차의 영향을 줄일 수 있다.
Ⅱ – 1. 무작위 오차의 유형
- 환경적 요인(Environmental Factors):
환경 조건이 미세하게 변동할 때 발생합니다. 예를 들어, 바람의 세기나 온도의 작은 변화 등이 측정 결과에 영향을 미칠 수 있다. - 계측기기의 한계(Limitations of Measuring Instruments):
기기의 해상도나 정밀도가 제한적일 경우 발생합니다. 예를 들어, 디지털 저울의 소수점 이하 자릿수가 제한되어 있는 경우이다. - 샘플 변동(Sample Variability):
샘플 자체가 일관되지 않을 때 발생합니다. 예를 들어, 동일한 화학물질이라도 미세하게 다른 특성을 보이는 경우이다. - 인간의 작은 실수(Human Minor Errors):
사람이 측정을 수행하면서 생기는 작은 실수들입니다. 예를 들어, 눈금 읽기의 미세한 오차나 손 떨림 등이 이에 해당한다.
Ⅱ – 2. 무작위 오차 최소화 전략
무작위 오차는 그 특성상 완전히 제거하기 어렵지만, 이를 최소화하기 위한 여러 가지 전략이 해야 합니다:
- 반복 측정(Repeated Measurements):
동일한 조건에서 여러 번 측정하여 평균값을 구함으로써 무작위 오차를 줄인다. - 고품질 장비 사용(Use of High-Quality Instruments):
정밀도가 높은 장비를 사용하여 계측기기의 한계를 극복한다. - 환경적 통제(Control Environmental Conditions):
가능한 환경 조건을 일정하게 유지하여 외부 요인의 영향을 최소화한다. - 표준 절차 준수(Adherence to Standard Procedures):
표준화된 절차를 엄격히 따름으로써 일관된 결과를 얻는다. - 데이터 처리(Data Processing Techniques):
통계적 방법을 활용하여 데이터 내의 무작위성을 분석하고 제거한다.
무작위 오차와 체계적 오차 모두 각각의 특성과 원인을 이해하고 적절히 대응하는 것이 연구 및 실험 결과의 정확성과 신뢰성을 높이는 핵심 요소이다.
함께 읽으면 좋은 글
핵심 확인 체크리스트
- 측정도구가 일관되게 사용되었는가?
- 응답자·조사환경·기록 과정에서 오차가 생길 가능성은 없는가?
- 무작위 오차와 체계적 오차를 구분했는가?
- 오차를 줄이기 위한 사전 점검 절차가 있는가?
함께 읽으면 좋은 R통계 글
- 연구란 무엇인가: R통계 입문을 위한 연구 개념 정리
- 변수와 측정 R통계: 독립변수·종속변수와 측정 수준 이해
- 타당성·신뢰성 R통계: 좋은 측정도구를 판단하는 기준
- 연구방법 R통계 입문: 연구 설계와 분석 방법을 한눈에 이해하기
FAQ
무작위 오차와 체계적 오차는 어떻게 다른가요?
무작위 오차는 우연한 변동 때문에 측정값이 흔들리는 것이고, 체계적 오차는 특정 방향으로 계속 치우치는 편향입니다. 두 오차는 원인과 줄이는 방법이 다릅니다.
측정오차는 연구 결과에 어떤 영향을 주나요?
측정오차가 크면 변수 간 관계가 약하게 보이거나 잘못된 결론으로 이어질 수 있습니다. 특히 체계적 오차는 결과 전체를 한쪽 방향으로 왜곡할 위험이 큽니다.
측정오차를 줄이려면 무엇을 확인해야 하나요?
측정도구의 문항, 조사 환경, 응답 방식, 기록 절차를 표준화해야 합니다. 사전 조사와 반복 측정을 통해 값이 안정적으로 나오는지도 확인하는 것이 좋습니다.